vault backup: 2025-03-17 00:41:03
This commit is contained in:
parent
8b4f9c3fa6
commit
f30332c441
File diff suppressed because one or more lines are too long
|
|
@ -1,7 +1,7 @@
|
|||
{
|
||||
"id": "dataview",
|
||||
"name": "Dataview",
|
||||
"version": "0.5.66",
|
||||
"version": "0.5.68",
|
||||
"minAppVersion": "0.13.11",
|
||||
"description": "Complex data views for the data-obsessed.",
|
||||
"author": "Michael Brenan <blacksmithgu@gmail.com>",
|
||||
|
|
|
|||
|
|
@ -1,8 +1,3 @@
|
|||
/** Live Preview padding fixes, specifically for DataviewJS custom HTML elements. */
|
||||
.is-live-preview .block-language-dataviewjs > p, .is-live-preview .block-language-dataviewjs > span {
|
||||
line-height: 1.0;
|
||||
}
|
||||
|
||||
.block-language-dataview {
|
||||
overflow-y: auto;
|
||||
}
|
||||
|
|
@ -74,7 +69,7 @@
|
|||
padding-right: 8px;
|
||||
font-family: var(--font-monospace);
|
||||
background-color: var(--background-primary-alt);
|
||||
color: var(--text-nav-selected);
|
||||
color: var(--nav-item-color-selected);
|
||||
}
|
||||
|
||||
.dataview.inline-field-value {
|
||||
|
|
@ -82,7 +77,7 @@
|
|||
padding-right: 8px;
|
||||
font-family: var(--font-monospace);
|
||||
background-color: var(--background-secondary-alt);
|
||||
color: var(--text-nav-selected);
|
||||
color: var(--nav-item-color-selected);
|
||||
}
|
||||
|
||||
.dataview.inline-field-standalone-value {
|
||||
|
|
@ -90,7 +85,7 @@
|
|||
padding-right: 8px;
|
||||
font-family: var(--font-monospace);
|
||||
background-color: var(--background-secondary-alt);
|
||||
color: var(--text-nav-selected);
|
||||
color: var(--nav-item-color-selected);
|
||||
}
|
||||
|
||||
/***************/
|
||||
|
|
|
|||
|
|
@ -11,6 +11,8 @@ kanban-plugin: board
|
|||
- WizNote
|
||||
- 云盘
|
||||
- [ ] 照片整理
|
||||
- [ ] dataview用起来,建立读书列表
|
||||
- [ ] 使用kanban整理物品
|
||||
|
||||
|
||||
## 读书
|
||||
|
|
|
|||
|
|
@ -0,0 +1,181 @@
|
|||
## 数据包接收流程
|
||||
|
||||
为了简单起见,我们将描述在物理网卡上接收和发送 Linux 网络数据包的过程,以 UDP 数据包处理过程为例,并尽量忽略一些无关的细节。
|
||||
|
||||
### 从网卡到内存
|
||||
|
||||
众所周知,每个网络设备(网卡)都有一个驱动程序来工作,并且该驱动程序需要在内核启动时加载到内核中。从逻辑上看,驱动程序是负责连接网络设备和内核[网络协议栈](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=%E7%BD%91%E7%BB%9C%E5%8D%8F%E8%AE%AE%E6%A0%88&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiLnvZHnu5zljY_orq7moIgiLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTI0OTcxNTgsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.zoOLcoxj24b3yATd7vMmKvqTM4mmRAlWKFjtJoO88Hw&zhida_source=entity)的中间模块。每当网络设备接收到一个新数据包时,它会触发一个中断,而相应的处理中断的程序正是加载到内核中的驱动程序。
|
||||
|
||||
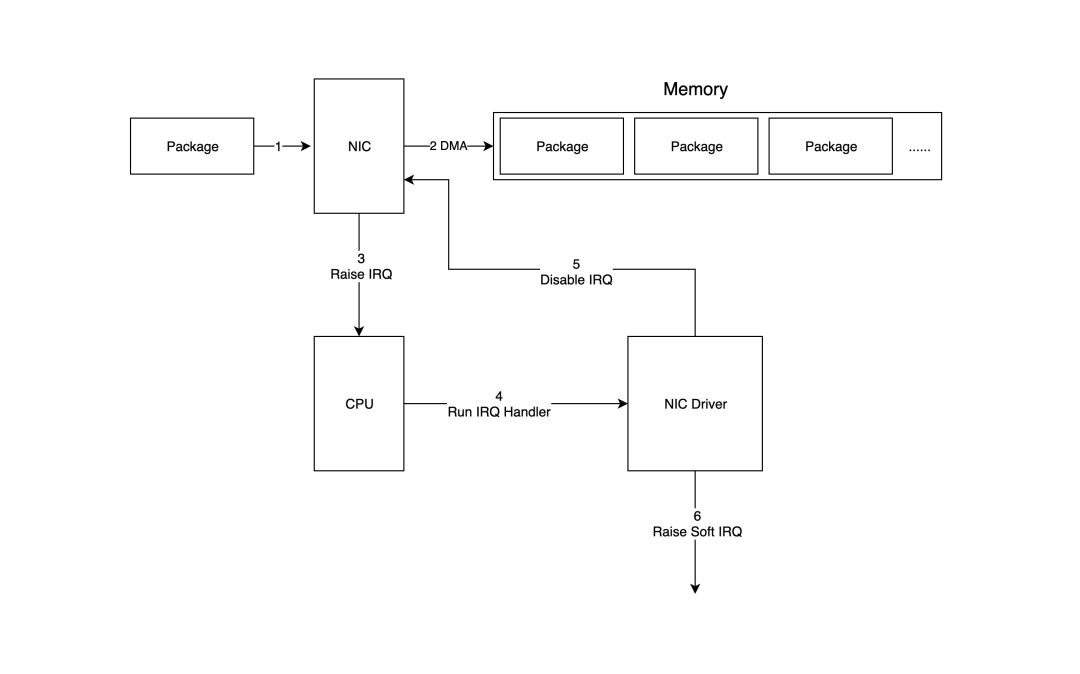
下图详细展示了数据包如何从网络设备进入系统内存,并由内核中的驱动程序和网络协议栈处理的过程。
|
||||
|
||||
|
||||
|
||||
1. 数据包进入物理网卡,如果目标地址不是该网络设备且该设备没有开启混杂模式,则数据包会被丢弃。
|
||||
|
||||
2. 物理网卡通过[DMA](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=DMA&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiJETUEiLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTI0OTcxNTgsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.-nXjUN8wbPK6ua46hGRJXREIevKAPJFm5JM96yTvoEM&zhida_source=entity)将数据包写入指定的内存地址,该地址由网卡驱动程序分配和初始化。
|
||||
|
||||
3. 物理网卡通过硬件中断(IRQ)通知CPU,有新数据包到达网卡并需要处理。
|
||||
|
||||
4. 接下来,CPU根据中断向量表调用已注册的中断函数,该中断函数将调用驱动程序(网卡驱动)中的相应函数。
|
||||
|
||||
5. 驱动程序首先禁用网卡的中断,表示驱动已经知道内存中有数据,并告诉物理网卡下次接收到数据包时直接写入内存,不要再通知CPU,以提高效率并避免CPU被不断中断。
|
||||
|
||||
6. 启动一个[软中断](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=%E8%BD%AF%E4%B8%AD%E6%96%AD&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiLova_kuK3mlq0iLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTI0OTcxNTgsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.ZpkMTIspRmKhzeOpsU4cOrd74DpXayEo6fHe_8Vu1VM&zhida_source=entity)以继续处理数据包。这样做的原因是硬件中断处理程序在执行过程中不能被中断,因此如果执行时间过长,会导致CPU无法响应其他硬件中断,所以内核引入了软中断,使得硬件中断处理程序中耗时的部分可以转移到软中断处理程序中慢慢处理。
|
||||
|
||||
|
||||
### 内核数据包处理
|
||||
|
||||
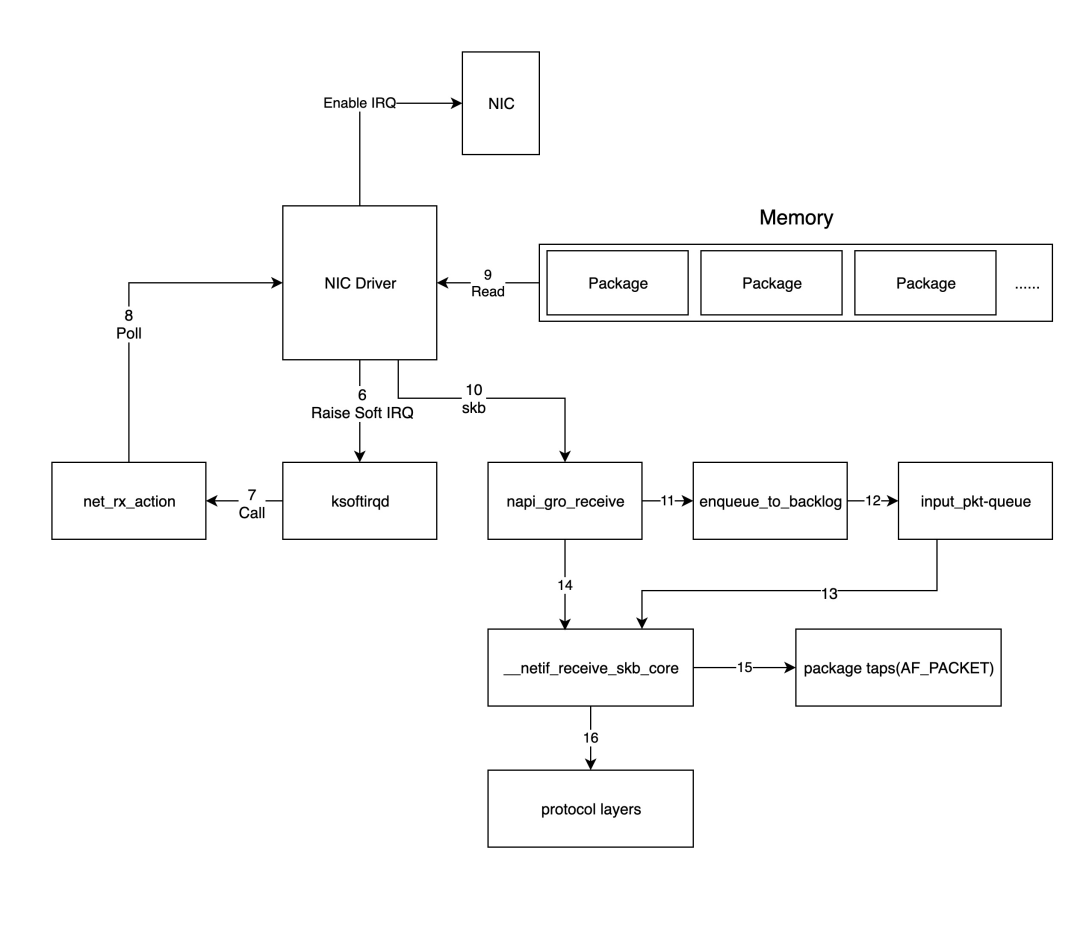
上一步中的网络设备驱动程序将通过触发内核网络模块中的软中断处理函数来处理数据包,内核处理数据包的过程如下图所示。
|
||||
|
||||
|
||||
|
||||
1. 对于上一步中驱动程序发出的软中断,内核中的 [ksoftirqd](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=ksoftirqd&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiJrc29mdGlycWQiLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTI0OTcxNTgsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.y98KSBNvEyQnV7f3Q8zAsAq-BpC1t-CHTQRdFQVbBho&zhida_source=entity) 进程会调用网络模块中相应的软中断处理函数,准确地说,这里调用的是`net_rx_action`函数。
|
||||
|
||||
2. `net_rx_action`随后会调用网卡驱动程序中的`poll`函数,逐个处理数据包。
|
||||
|
||||
3. `poll`函数会让驱动程序读取网卡写入内存的数据包,实际上,内存中数据包的格式只有驱动程序知道;
|
||||
|
||||
4. 驱动程序将内存中的数据包转换为内核网络模块识别的`skb`(socket buffer)格式,然后调用`[napi_gro_receive](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=napi_gro_receive&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiJuYXBpX2dyb19yZWNlaXZlIiwiemhpZGFfc291cmNlIjoiZW50aXR5IiwiY29udGVudF9pZCI6MjUyNDk3MTU4LCJjb250ZW50X3R5cGUiOiJBcnRpY2xlIiwibWF0Y2hfb3JkZXIiOjEsInpkX3Rva2VuIjpudWxsfQ.tiI07qTKsomFW4GH4XjrAm_5OgFk2EU8bUAMoUqWKic&zhida_source=entity)`函数。
|
||||
|
||||
5. `napi_gro_receive`函数会处理GRO(Generic Receive Offload)相关的内容,即合并可以合并的数据包,从而只需调用一次协议栈,然后判断是否启用了 [RPS](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=RPS&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiJSUFMiLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTI0OTcxNTgsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.LaPiYE2m6spYYinzd-8sMVkrv2AQ0zShqCf8eEHrxZE&zhida_source=entity)(Receive Packet Steering);如果启用了,则会调用`enqueue_to_backlog`函数。
|
||||
|
||||
6. `enqueue_to_backlog`函数会将数据包放入`input_pkt_queue`结构中并返回。
|
||||
|
||||
注意:如果`input_pkt_queue`已满,数据包将被丢弃,该队列的大小可以通过`net.core.netdev_max_backlog`配置。
|
||||
|
||||
7. 随后,CPU 会在软中断上下文中处理其`input_pkt_queue`中的网络数据,实际上是通过调用`__netif_receive_skb_core`函数来完成。
|
||||
|
||||
8. 如果未启用RPS,`napi_gro_receive`函数会直接调用`__netif_receive_skb_core`函数来处理网络数据包。
|
||||
|
||||
9. 紧接着,如果存在类型为`AF_PACKET`的原始套接字(raw socket),CPU会将数据复制一份到该套接字中(tcpdump 捕获的数据包就是这种数据包)。
|
||||
|
||||
10. 将数据包传递给内核的 TCP/IP 协议栈进行处理。
|
||||
|
||||
|
||||
当内存中的所有数据包都处理完毕(`poll`函数执行完成)后,重新启用网卡的硬件中断,以便下次网卡再次接收到数据时通知CPU。
|
||||
|
||||
### 内核网络协议栈
|
||||
|
||||
此时,内核 TCP/IP 协议栈接收到的数据包实际上是第3层(网络层)的数据包,所以数据包将首先到达 IP 网络层,然后再传递到传输层进行处理。
|
||||
|
||||
#### IP网络层
|
||||
|
||||
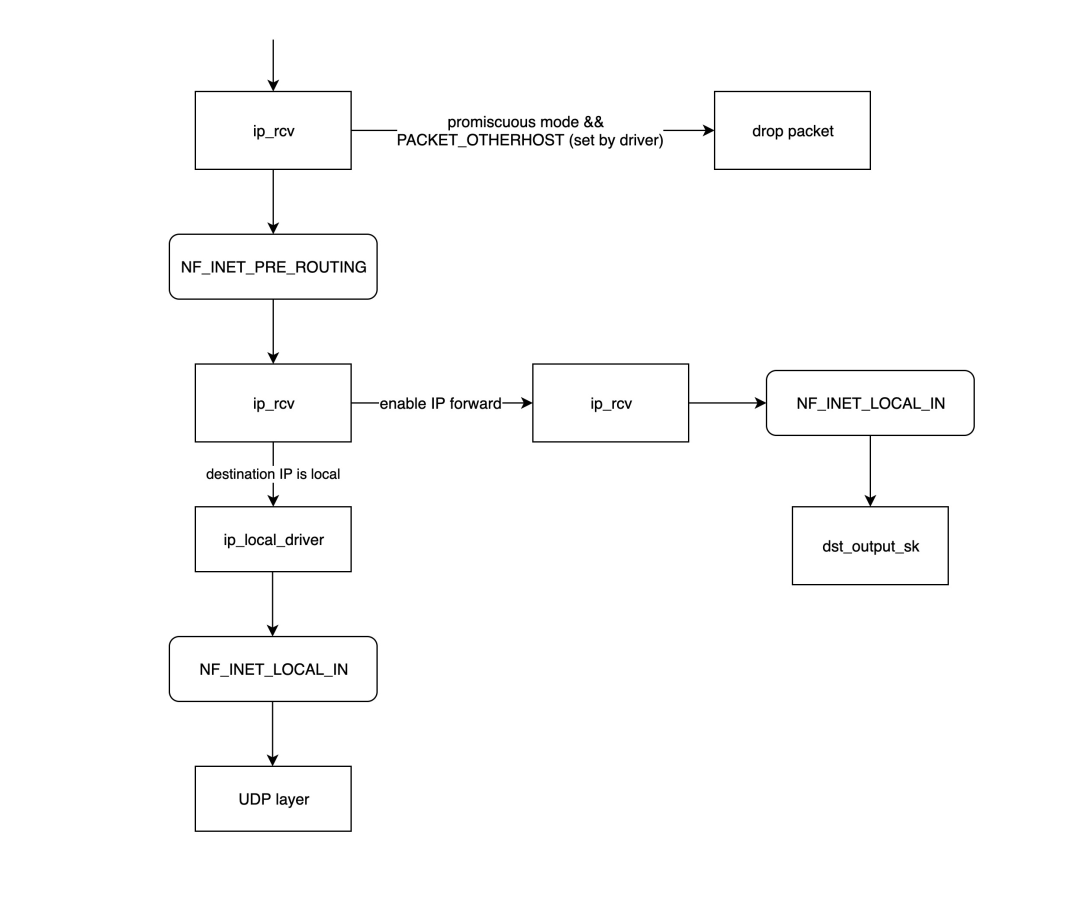
|
||||
|
||||
- `ip_rcv`是 IP 网络层处理模块的入口函数,它首先确定数据包是否需要被丢弃(目标 MAC 地址不是当前网卡且网卡未设置为混杂模式),如果需要进一步处理,则调用在 [netfilter](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=netfilter&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiJuZXRmaWx0ZXIiLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTI0OTcxNTgsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.OqycFsOApizrQuazM4MYPt_jI3UVAoaUUvN6CiNw2aY&zhida_source=entity) 中注册的`[NF_INET_PRE_ROUTING](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=NF_INET_PRE_ROUTING&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiJORl9JTkVUX1BSRV9ST1VUSU5HIiwiemhpZGFfc291cmNlIjoiZW50aXR5IiwiY29udGVudF9pZCI6MjUyNDk3MTU4LCJjb250ZW50X3R5cGUiOiJBcnRpY2xlIiwibWF0Y2hfb3JkZXIiOjEsInpkX3Rva2VuIjpudWxsfQ.x1YIlAnehTkjllddwWzQAwUaqQcn_CEBplw0puyUJ3s&zhida_source=entity)`链中的处理函数。
|
||||
|
||||
- `NF_INET_PRE_ROUTING`是 netfilter 在协议栈中放置的一个钩子函数,通过 iptables 注入一些数据包处理函数来修改或丢弃数据包。如果数据包未被丢弃,将继续向下传递。
|
||||
|
||||
netfilter 链中的处理逻辑,如`NF_INET_PRE_ROUTING`,可以通过 iptables 进行设置。
|
||||
|
||||
- 路由处理:如果目标 IP 不是本地 IP 且未启用 IP 转发,则数据包将被丢弃;否则,数据包将传递到`ip_forward`函数进行转发处理。
|
||||
|
||||
- `ip_forward`函数将首先调用 netfilter 在`[NF_INET_FORWARD](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=NF_INET_FORWARD&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiJORl9JTkVUX0ZPUldBUkQiLCJ6aGlkYV9zb3VyY2UiOiJlbnRpdHkiLCJjb250ZW50X2lkIjoyNTI0OTcxNTgsImNvbnRlbnRfdHlwZSI6IkFydGljbGUiLCJtYXRjaF9vcmRlciI6MSwiemRfdG9rZW4iOm51bGx9.ZWVB2LHebelQ9B-Np1mNpzQ4AQyA3H0VRcdfobNMgNM&zhida_source=entity)`链中注册的处理函数,如果数据包未被丢弃,将继续调用`dst_output_sk`函数。
|
||||
|
||||
- `dst_output_sk`函数将调用 IP 网络层的适当函数来发送数据包,此步骤的详细内容将在下一节关于发送数据包的部分中描述。
|
||||
|
||||
- `ip_local_deliver`:如果上述路由处理发现目标 IP 是本地网卡的 IP,则将调用`ip_local_deliver`函数,该函数首先调用`[NF_INET_LOCAL_IN](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=NF_INET_LOCAL_IN&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiJORl9JTkVUX0xPQ0FMX0lOIiwiemhpZGFfc291cmNlIjoiZW50aXR5IiwiY29udGVudF9pZCI6MjUyNDk3MTU4LCJjb250ZW50X3R5cGUiOiJBcnRpY2xlIiwibWF0Y2hfb3JkZXIiOjEsInpkX3Rva2VuIjpudWxsfQ.RxOHbmMBa9x3WswoKqN9OvauySvC-BGZ8r-KNbVZyp4&zhida_source=entity)`链中相关的处理函数,如果通过,则将数据包传递到传输层。
|
||||
|
||||
|
||||
#### 传输层
|
||||
|
||||
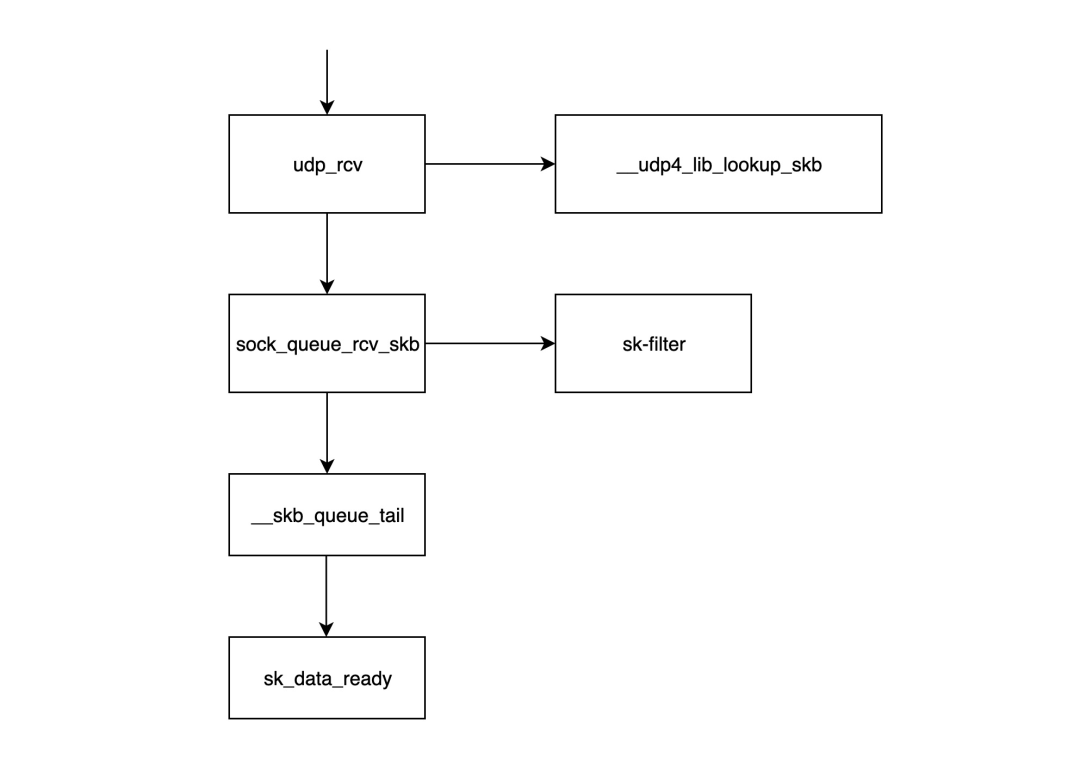
|
||||
|
||||
- `udp_rcv`函数是 UDP 处理层模块的入口函数,它首先调用`__udp4_lib_lookup_skb`函数,根据目标 IP 和端口查找对应的套接字(所谓的套接字基本上是由 IP+端口组成的结构)。如果未找到对应的套接字,则数据包将被丢弃;否则,继续处理。
|
||||
|
||||
- `sock_queue_rcv_skb`函数首先检查套接字的接收缓存是否已满,如果已满则丢弃数据包;其次,它调用`sk_filter`检查数据包是否符合条件。如果当前套接字上设置了过滤器且数据包不符合条件,则数据包也会被丢弃。
|
||||
|
||||
|
||||
> sk_filter 函数是 Linux 内核中用于套接字过滤(Socket Filtering)的一个接口。它允许应用程序在数据包到达用户空间之前,在内核空间对数据包进行过滤。这个函数的主要目的是执行与给定套接字关联的BPF过滤器程序。具体实现参考 net/core/filter.c 中的`sk_filter_trim_cap`函数。
|
||||
|
||||
- `__skb_queue_tail`函数将数据包放入套接字的接收队列末尾。
|
||||
|
||||
- `sk_data_ready`通知套接字数据包已准备好。
|
||||
|
||||
- 调用`sk_data_ready`后,一个数据包处理完毕,等待应用层读取。
|
||||
|
||||
|
||||
注意:上述所有执行过程都在软中断上下文中进行。
|
||||
|
||||
## 数据包的发送流程
|
||||
|
||||
从逻辑上讲,Linux 网络数据包的发送过程与接收过程相反,因此,我们仍然以通过物理网卡发送 UDP 数据包为例进行说明。
|
||||
|
||||
### 应用层
|
||||
|
||||
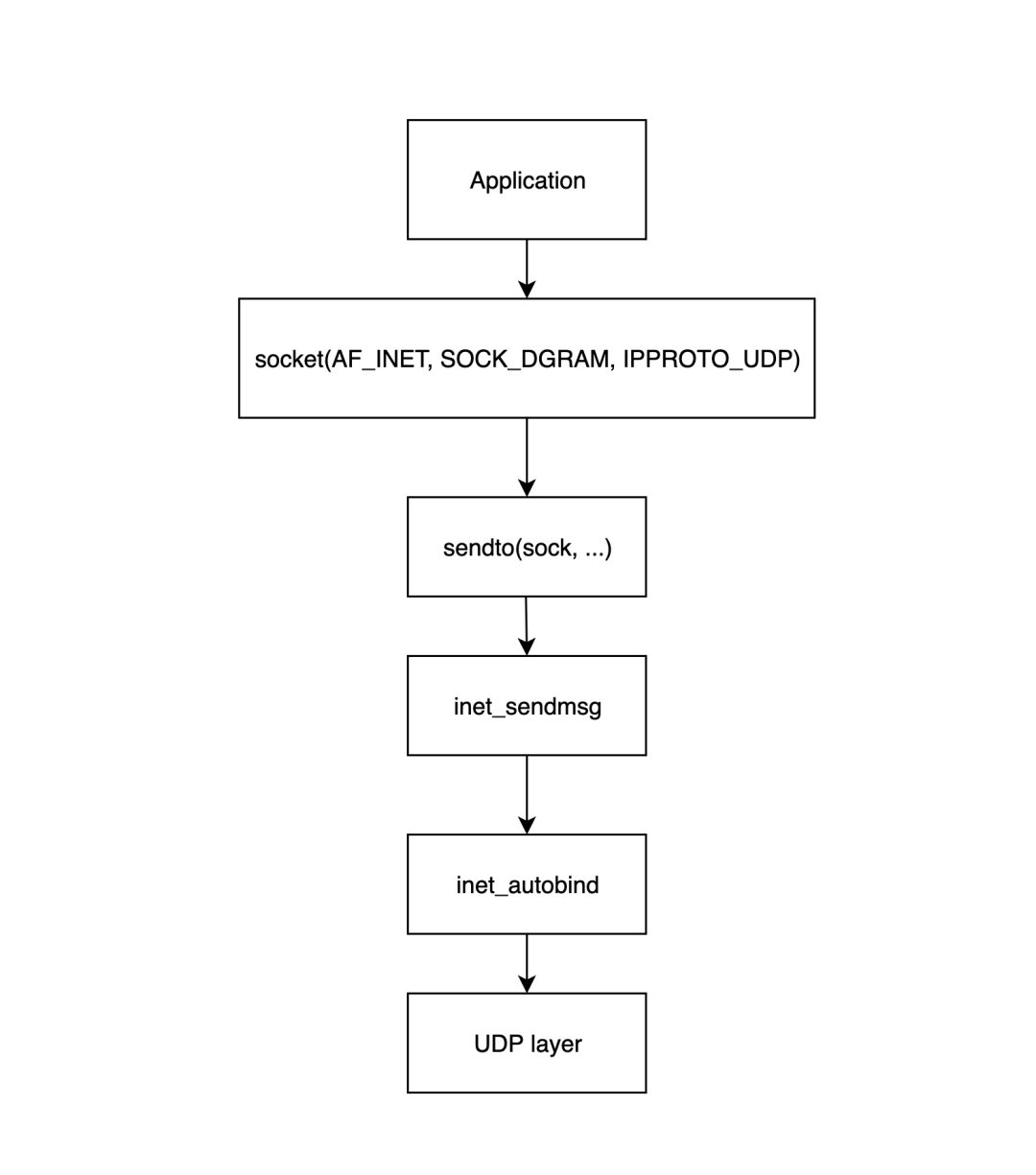
应用层的开始是应用程序调用 Linux 网络接口创建套接字,下图详细展示了应用层如何构建套接字并将其发送到传输层。
|
||||
|
||||
|
||||
|
||||
- 调用`socket%28...%29`来创建一个套接字结构并初始化相应的操作函数。
|
||||
|
||||
- `sendto%28sock, ...%29`由应用层程序调用以开始发送数据包;此函数调用后面的`inet_sendmsg`函数。
|
||||
|
||||
- `inet_sendmsg`此函数主要检查当前套接字是否绑定了源端口,如果没有,则调用`inet_autobind`函数分配一个端口,然后调用 UDP 层函数进行传输。
|
||||
|
||||
- `inet_autobind`函数将调用`get_port`函数以获取一个可用的端口。
|
||||
|
||||
|
||||
### 传输层
|
||||
|
||||
|
||||
|
||||
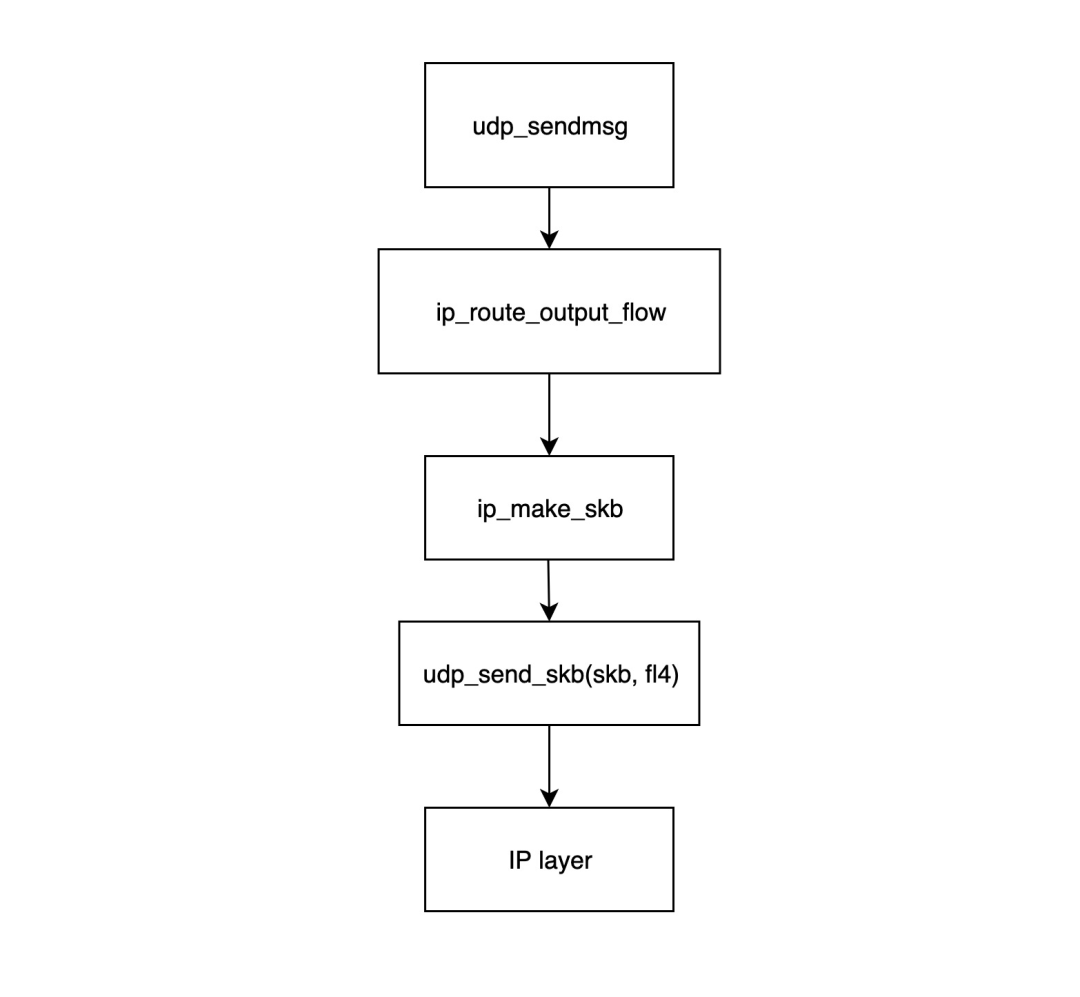
- `udp_sendmsg`函数是 UDP 传输层模块发送数据包的入口点。该函数首先调用`ip_route_output_flow`函数获取路由信息(主要是源 IP 和网卡),然后调用`ip_make_skb`构造`skb`结构,最后将网卡信息与`skb`关联。
|
||||
|
||||
- `ip_route_output_flow`函数主要处理路由信息,它将根据路由表和目标 IP 确定数据包应从哪个网络设备发送。如果套接字未绑定源 IP,该函数还将根据路由表为其找到最合适的源 IP。如果套接字绑定了源 IP,但根据路由表,与该源 IP 对应的网卡无法到达目标地址,则数据包将被丢弃,并返回错误以表示发送失败。该函数最终将找到的网络设备和源 IP 填充到`flowi4`结构中,并将其返回给`udp_sendmsg`函数。
|
||||
|
||||
- `ip_make_skb`函数使用分配的 IP 数据包头(包括源 IP 信息)构造`skb`数据包,并调用`__ip_append_dat`函数对数据包进行切片,检查套接字的发送缓存是否已耗尽,如果已耗尽则返回`ENOBUFS`错误消息。
|
||||
|
||||
- `udp_send_skb%28skb, fl4%29`函数用 UDP 数据包头填充`skb`并处理校验和,然后将其传递给 IP 网络层中的相应函数。
|
||||
|
||||
|
||||
### IP 网络层
|
||||
|
||||
|
||||
|
||||
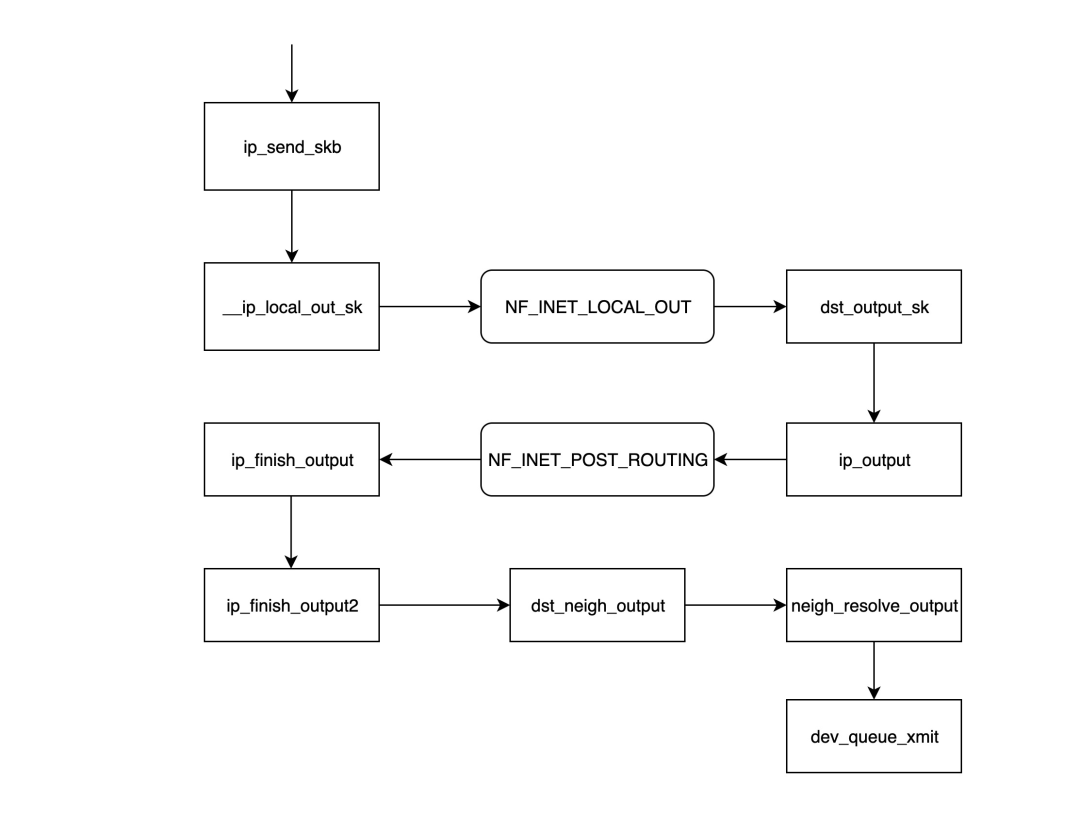
- `ip_send_skb`是 IP 网络层模块发送数据包的入口函数,它实质上调用后面的一系列函数来发送网络层数据包。
|
||||
|
||||
- `__ip_local_out_sk`函数用于设置 IP 数据包头的长度和校验和值,然后调用在`NF_INET_LOCAL_OUT`钩子链上注册的后续处理函数。
|
||||
|
||||
- `NF_INET_LOCAL_OUT`是一个 netfilter 钩子门,可以通过 iptables 配置链上的处理函数;如果数据包未被丢弃,将继续沿链传递。
|
||||
|
||||
- `dst_output_sk`函数根据`skb`内部的信息调用相应的输出函数`ip_output`。
|
||||
|
||||
- `ip_output`函数将前一层`udp_sendmsg`获取的网卡信息写入`skb`,然后调用在`[NF_INET_POST_ROUTING](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=NF_INET_POST_ROUTING&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiJORl9JTkVUX1BPU1RfUk9VVElORyIsInpoaWRhX3NvdXJjZSI6ImVudGl0eSIsImNvbnRlbnRfaWQiOjI1MjQ5NzE1OCwiY29udGVudF90eXBlIjoiQXJ0aWNsZSIsIm1hdGNoX29yZGVyIjoxLCJ6ZF90b2tlbiI6bnVsbH0.NCFqIOnFlYtze0wrolgwpJYn67FzqGOWXhXkHEIe8rM&zhida_source=entity)`钩子链上注册的处理函数。%2A`NF_INET_POST_ROUTING`是 netfilter 钩子链`NF_INET_POST_ROUTING`。
|
||||
|
||||
- `NF_INET_POST_ROUTING`是一个 netfilter 钩子门,可以通过 iptables 配置链上的处理函数;在这个步骤中,主要配置源地址转换(SNAT),这会导致此`skb`的路由信息发生变化。
|
||||
|
||||
- `ip_finish_output`函数确定自上一步以来路由信息是否已发生变化,如果已变化,则需要再次调用`dst_output_sk`函数(当此函数再次被调用时,可能不会进入调用`ip_output`函数的分支,而是进入 netfilter 指定的输出函数,可能是`xfrm4_transport_output`),否则将继续传递。
|
||||
|
||||
- `ip_finish_output2`函数根据目标 IP 在路由表中查找下一跳地址,然后调用`__ipv4_neigh_lookup_noref`函数在 [ARP 表](https://zhida.zhihu.com/search?content_id=252497158&content_type=Article&match_order=1&q=+ARP+%E8%A1%A8&zd_token=eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpc3MiOiJ6aGlkYV9zZXJ2ZXIiLCJleHAiOjE3NDIzMTMwNzAsInEiOiIgQVJQIOihqCIsInpoaWRhX3NvdXJjZSI6ImVudGl0eSIsImNvbnRlbnRfaWQiOjI1MjQ5NzE1OCwiY29udGVudF90eXBlIjoiQXJ0aWNsZSIsIm1hdGNoX29yZGVyIjoxLCJ6ZF90b2tlbiI6bnVsbH0.E--XksHr9lcG5NIqIRCiIP2D3FUdPO9xxIUROB7bXtY&zhida_source=entity)中查找下一跳的邻居信息,如果未找到,则调用`__neigh_create`函数构建一个空的邻居结构。
|
||||
|
||||
- `dst_neigh_output`函数调用`neigh_resolve_output`函数获取邻居信息,并用其中的 MAC 地址填充`skb`,然后调用`dev_queue_xmit`函数发送数据包。
|
||||
|
||||
|
||||
### 内核处理数据包
|
||||
|
||||
|
||||
|
||||
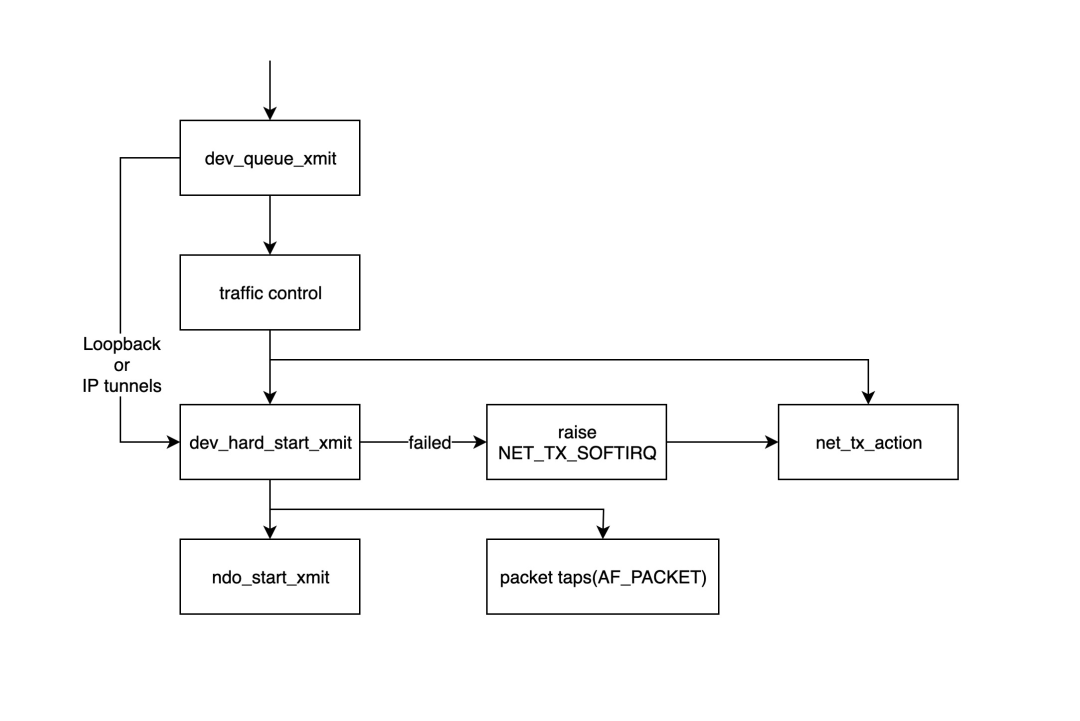
- `dev_queue_xmit`函数是内核模块开始处理发送数据包的入口点,此函数将首先获取设备的相应队列规则(qdisc),如果没有(例如环回接口或 IP 隧道),则会直接调用`dev_hard_start_xmit`函数,否则数据包将通过流量控制%28TC%29模块进行处理。
|
||||
|
||||
- 流量控制模块主要负责过滤和排序数据包,如果队列已满,数据包将被丢弃,详情请参阅:[http://tldp.org/HOWTO/Traffic-Control-HOWTO/intro.html](https://link.zhihu.com/?target=http%3A//tldp.org/HOWTO/Traffic-Control-HOWTO/intro.html)
|
||||
|
||||
- `dev_hard_start_xmit`函数首先将`skb`的一个副本复制到“数据包探针”(`tcpdump`命令从这里获取数据包),然后调用`ndo_start_xmit`函数发送数据包。如果`dev_hard_start_xmit`函数返回错误,调用它的函数会将`skb`放置在某个位置,并抛出一个软中断`NET_TX_SOFTIRQ`到软中断处理函数`net_tx_action`,以便稍后重试处理。
|
||||
|
||||
- `ndo_start_xmit`函数绑定到特定驱动程序处理发送数据的处理函数。
|
||||
|
||||
|
||||
**注意**:`ndo_start_xmit`函数将指向特定网卡驱动程序以发送数据包,在此步骤之后,发送数据包的任务将交给网络设备驱动程序,不同的网络设备驱动程序有不同的处理方式,但整体流程基本相同。
|
||||
|
||||
- 将`skb`放入网卡的传输队列。
|
||||
|
||||
- 通知网卡发送数据包。
|
||||
|
||||
- 网卡发送完成后向 CPU 发送中断。
|
||||
|
||||
- 收到中断后清理`skb`。
|
||||
|
||||
|
||||
## Source
|
||||
|
||||
[https://www.sobyte.net/post/2022-10/linux-net-snd-rcv/](https://link.zhihu.com/?target=https%3A//www.sobyte.net/post/2022-10/linux-net-snd-rcv/)
|
||||
|
|
@ -25,69 +25,36 @@
|
|||
- 用户目录,它是可选的,对于每个普通用户,在/home目录下都有一个以用户名命名的子目录,里面存放用户相关的~~配置文件~~。用户文件。
|
||||
- /root目录
|
||||
- 根用户的目录,与此对应,普通用户的目录是/home下的某个子目录。
|
||||
- /usr目录
|
||||
/usr目录的内容可以存在另一个分区中,在系统启动后再挂接到根文件系统中的/usr目录下。里面存放的是共享、只读的程序和数据,这表明/usr目录下的内容可以在多个主机间共享,这些主要也符合FHS标准的。/usr中的文件应该是只读的,其他主机相关的,可变的文件应该保存在其他目录下,比如/var。/usr目录在嵌入式中可以精减。
|
||||
9、 /var目录
|
||||
与/usr目录相反,/var目录中存放可变的数据,比如spool目录(mail,news),log文件,临时文件。
|
||||
10、/proc目录
|
||||
这是一个空目录,常作为proc文件系统的挂接点,proc文件系统是个虚拟的文件系统,它没有实际的存储设备,里面的目录,文件都是由内核
|
||||
- /usr目录 *静态的只读数据*
|
||||
- /usr目录的内容可以存在另一个分区中,在系统启动后再挂接到根文件系统中的/usr目录下。里面存放的是共享、只读的程序和数据,这表明/usr目录下的内容可以在多个主机间共享,这些主要也符合FHS标准的。/usr中的文件应该是只读的,其他主机相关的,可变的文件应该保存在其他目录下,比如/var。/usr目录在嵌入式中可以精减。
|
||||
- /var目录 */var(Variable Data)专用于存储 运行时动态生成的数据,其核心特点是 频繁变化 和 不可共享性*
|
||||
- 与/usr目录相反,/var目录中存放可变的数据,比如spool目录(mail,news),log文件,临时文件。
|
||||
- /proc目录
|
||||
- 这是一个空目录,常作为proc文件系统的挂接点,proc文件系统是个虚拟的文件系统,它没有实际的存储设备,里面的目录,文件都是由内核临时生成的,用来表示系统的运行状态,也可以操作其中的文件控制系统。
|
||||
- /mnt目录
|
||||
- 用于临时挂载某个文件系统的挂接点,通常是空目录,也可以在里面创建一引起空的子目录,比如/mnt/cdram /mnt/hda1 。用来临时挂载光盘硬盘、
|
||||
- /tmp目录
|
||||
- 用于存放临时文件,通常是空目录,一些需要生成临时文件的程序用到的/tmp目录下,所以/tmp目录必须存在并可以访问。
|
||||
- /sys目录 *原文没写,比较复杂得单独写 * #未完成
|
||||
|
||||
临时生成的,用来表示系统的运行状态,也可以操作其中的文件控制系统。
|
||||
11、 /mnt目录
|
||||
用于临时挂载某个文件系统的挂接点,通常是空目录,也可以在里面创建一引起空的子目录,比如/mnt/cdram /mnt/hda1 。用来临时挂载光盘
|
||||
- 那我们利用Busybox制作根文件系统就是创建这上面的这些目录,和这些目录下面的各种文件。 对于嵌入式Linux系统的根文件系统来说,一般可能没有上面所列出的那么复杂,比如嵌入式系统通常都不是针对多用户的,所以/home这个目录在一般嵌入式Linux中可能就很少用到,而/boot这个目录则取决于你所使用的BootLoader是否能够重新获得内核映象从你的根文件系统在内核启动之前。一般说来,只有/bin,/dev,/etc,/lib,/proc,/var,/usr这些需要的,而其他都是可选的。
|
||||
|
||||
。硬盘、
|
||||
12. /tmp目录
|
||||
用于存放临时文件,通常是空目录,一些需要生成临时文件的程序用到的/tmp目录下,所以/tmp目录必须存在并可以访问。
|
||||
那我们利用Busybox制作根文件系统就是创建这上面的这些目录,和这些目录下面的各种文件。
|
||||
对于嵌入式Linux系统的根文件系统来说,一般可能没有上面所列出的那么复杂,比如嵌入式系统通常都不是针对多用户的,所以/home这个目录在一般嵌入式Linux中可能就很少用到,而/boot这个目录则取决于你所使用的BootLoader是否能够重新获得内核映象从你的根文件系统在内核启动之前。一般说来,只有/bin,/dev,/etc,/lib,/proc,/var,/usr这些需要的,而其他都是可选的。
|
||||
|
||||
根文件系统一直以来都是所有类Unix操作系统的一个重要组成部分,也可以认为是嵌入式Linux系统区别于其他一些传统嵌入式操作系统的重要特征,它给 Linux带来了许多强大和灵活的功能,同时也带来了一些复杂性。我们需要清楚的了解根文件系统的基本结构,以及细心的选择所需要的系统库、内核模块和应用程序等,并配置好各种初始化脚本文件,以及选择合适的文件系统类型并把它放到实际的存储设备的合适
|
||||
|
||||
位置,下面是几中比较常用的文件系统。
|
||||
(1) jffs2
|
||||
|
||||
JFFS嵌入式系统文件系统最早是由瑞典 Axis Communications公司基于Linux2.0的内核为嵌入式系统开发的文件系统。JFFS2是RedHat公司
|
||||
|
||||
基于JFFS开发的闪存文件系统,最初是针对RedHat公司的嵌入式产品eCos开发的嵌入式文件系统,所以JFFS2也可以用在Linux, uCLinux中。
|
||||
|
||||
Jffs2: 日志闪存嵌入式系统文件系统版本2 (Journalling Flash FileSystem v2)
|
||||
|
||||
主要用于NOR型闪存,基于MTD驱动层,特点是:可读写的、支持数据压缩的、基于哈希表的日志型文件系统,并提供了崩溃/掉电安全保护
|
||||
|
||||
,提供“写平衡”支持等。缺点主要是当文件系统已满或接近满时,因为垃圾收集的关系而使jffs2的运行速度大大放慢。目前jffs3正在开发
|
||||
|
||||
中。关于jffs系列文件系统的使用详细文档,可参考MTD补丁包中mtd-jffs-HOWTO.txt。
|
||||
|
||||
jffsx不适合用于NAND闪存主要是因为NAND闪存的容量一般较大,这样导致jffs为维护日志节点所占用的内存空间迅速增大,另外,jffsx
|
||||
|
||||
文件系统在挂载时需要扫描整个FLASH的内容,以找出所有的日志节点,建立文件结构,对于大容量的NAND闪存会耗费大量时间。
|
||||
|
||||
(2) yaffs:Yet Another Flash File System
|
||||
|
||||
yaffs/yaffs2是专为嵌入式系统使用 NAND型闪存而设计的一种日志型文件系统。与jffs2相比,它减少了一些功能(例如不支持数据压缩),所以速度更快,挂载时间很短,对内存的占用较小。另外,它还是跨平台的文件系统,除了Linux和eCos,还支持WinCE, pSOS和ThreadX等。
|
||||
|
||||
yaffs/yaffs2自带NAND芯片的驱动,并且为嵌入式系统提供了直接访问文件系统的API,用户可以不使用Linux中的MTD与VFS,直接对文件系统操作。当然,yaffs也可与MTD驱动程序配合使用。
|
||||
|
||||
yaffs与 yaffs2的主要区别在于,前者仅支持小页(512 Bytes) NAND闪存,后者则可支持大页(2KB) NAND闪存。同时,yaffs2在内存空间
|
||||
|
||||
占用、垃圾回收速度、读/写速度等方面均有大幅提升。
|
||||
|
||||
(3) Cramfs:Compressed ROM File System
|
||||
|
||||
Cramfs是Linux的创始人 Linus Torvalds参与开发的一种只读的压缩文件系统。它也基于MTD驱动程序。在cramfs文件系统中,每一页(4KB)被单独压缩,可以随机页访问,其压缩比高达2:1,为嵌入式系统节省大量的Flash存储空间,使系统可通过更低容量的FLASH存储相同的文件,从而降低系统成本。
|
||||
|
||||
Cramfs文件系统以压缩方式存储,在运行时解压缩,所以不支持应用程序以XIP方式运行,所有的应用程序要求被拷到RAM里去运行,但这
|
||||
|
||||
并不代表比 Ramfs需求的RAM空间要大一点,因为Cramfs是采用分页压缩的方式存放档案,在读取档案时,不会一下子就耗用过多的内存空间,
|
||||
|
||||
只针对目前实际读取的部分分配内存,尚没有读取的部分不分配内存空间,当我们读取的档案不在内存时,Cramfs文件系统自动计算压缩后的
|
||||
|
||||
资料所存的位置,再即时解压缩到 RAM中。另外,它的速度快,效率高,其只读的特点有利于保护文件系统免受破坏,提高了系统的可靠性。
|
||||
|
||||
由于以上特性,Cramfs在嵌入式系统中应用广泛。但是它的只读属性同时又是它的一大缺陷,使得用户无法对其内容对进扩充。Cramfs映像通
|
||||
|
||||
常是放在Flash中,但是也能放在别的文件系统里,使用 loopback 设备可以把它安装别的文件系统里。
|
||||
|
||||
(4) 网络文件系统NFS (Network File System)
|
||||
NFS是由Sun开发并 发展起来的一项在不同机器、不同操作系统之间通过网络共享文件的技术。在嵌入式Linux系统的开发调试阶段,可以利用该技术在主机上建立基于NFS 的根文件系统,挂载到嵌入式设备,可以很方便地修改根文件系统的内容。以上讨论的都是基于存储设备的文件系统(memory-based file system),它们都可用作Linux的根文件系统。实际上,Linux还支持逻辑的或伪文件系统(logical or pseudo file system),例如procfs(proc文件系统),用于获取系统信息,以及devfs(设备文件系统)和sysfs,用于维护设备文件。
|
||||
- 根文件系统一直以来都是所有类Unix操作系统的一个重要组成部分,也可以认为是嵌入式Linux系统区别于其他一些传统嵌入式操作系统的重要特征,它给 Linux带来了许多强大和灵活的功能,同时也带来了一些复杂性。我们需要清楚的了解根文件系统的基本结构,以及细心的选择所需要的系统库、内核模块和应用程序等,并配置好各种初始化脚本文件,以及选择合适的文件系统类型并把它放到实际的存储设备的合适位置,下面是几中比较常用的文件系统。
|
||||
- JFFS2
|
||||
- JFFS嵌入式系统文件系统最早是由瑞典 Axis Communications公司基于Linux2.0的内核为嵌入式系统开发的文件系统。JFFS2是RedHat公司基于JFFS开发的闪存文件系统,最初是针对RedHat公司的嵌入式产品eCos开发的嵌入式文件系统,所以JFFS2也可以用在Linux, uCLinux中。
|
||||
- Jffs2: ==日志闪存==嵌入式系统文件系统版本2 (Journalling Flash FileSystem v2==)主要用于NOR型闪存==,基于MTD驱动层,特点是:可读写的、支持数据压缩的、基于哈希表的日志型文件系统,并提供了崩溃/掉电安全保护,提供“写平衡”支持等。缺点主要是当文件系统已满或接近满时,因为垃圾收集的关系而使jffs2的运行速度大大放慢。目前jffs3正在开发中。关于jffs系列文件系统的使用详细文档,可参考MTD补丁包中mtd-jffs-HOWTO.txt。
|
||||
- ==jffsx不适合用于NAND闪存==主要是因为NAND闪存的容量一般较大,这样导致jffs为维护日志节点所占用的内存空间迅速增大,另外,jffsx文件系统在挂载时需要扫描整个FLASH的内容,以找出所有的日志节点,建立文件结构,对于大容量的NAND闪存会耗费大量时间。
|
||||
- yaffs:Yet Another Flash File System
|
||||
- yaffs/yaffs2是专为嵌入式系统使用 NAND型闪存而设计的一种日志型文件系统。与jffs2相比,它减少了一些功能(例如不支持数据压缩),所以速度更快,挂载时间很短,对内存的占用较小。另外,它还是跨平台的文件系统,除了Linux和eCos,还支持WinCE, pSOS和ThreadX等。
|
||||
- yaffs/yaffs2自带NAND芯片的驱动,并且为嵌入式系统提供了直接访问文件系统的API,用户可以不使用Linux中的MTD与VFS,直接对文件系统操作。当然,yaffs也可与MTD驱动程序配合使用。
|
||||
- yaffs与 yaffs2的主要区别在于,前者仅支持小页(512 Bytes) NAND闪存,后者则可支持大页(2KB) NAND闪存。同时,yaffs2在内存空间占用、垃圾回收速度、读/写速度等方面均有大幅提升。
|
||||
- Cramfs:Compressed ROM File System
|
||||
- Cramfs是Linux的创始人 Linus Torvalds参与开发的一种只读的压缩文件系统。它也基于MTD驱动程序。在cramfs文件系统中,每一页(4KB)被单独压缩,可以随机页访问,其压缩比高达2:1,为嵌入式系统节省大量的Flash存储空间,使系统可通过更低容量的FLASH存储相同的文件,从而降低系统成本。
|
||||
- Cramfs文件系统以压缩方式存储,在运行时解压缩,所以不支持应用程序以XIP方式运行,所有的应用程序要求被拷到RAM里去运行,但这并不代表比 Ramfs需求的RAM空间要大一点,因为Cramfs是采用分页压缩的方式存放档案,在读取档案时,不会一下子就耗用过多的内存空间,只针对目前实际读取的部分分配内存,尚没有读取的部分不分配内存空间,当我们读取的档案不在内存时,Cramfs文件系统自动计算压缩后的资料所存的位置,再即时解压缩到 RAM中。另外,它的速度快,效率高,其只读的特点有利于保护文件系统免受破坏,提高了系统的可靠性。由于以上特性,Cramfs在嵌入式系统中应用广泛。但是它的只读属性同时又是它的一大缺陷,使得用户无法对其内容对进扩充。Cramfs映像通常是放在Flash中,但是也能放在别的文件系统里,使用 loopback 设备可以把它安装别的文件系统里。
|
||||
- 网络文件系统NFS (Network File System)
|
||||
- NFS是由Sun开发并 发展起来的一项在不同机器、不同操作系统之间通过网络共享文件的技术。在嵌入式Linux系统的开发调试阶段,可以利用该技术在主机上建立基于NFS 的根文件系统,挂载到嵌入式设备,可以很方便地修改根文件系统的内容。以上讨论的都是基于存储设备的文件系统(memory-based file system),它们都可用作Linux的根文件系统。实际上,Linux还支持逻辑的或伪文件系统(logical or pseudo file system),例如procfs(proc文件系统),用于获取系统信息,以及devfs(设备文件系统)和sysfs,用于维护设备文件。
|
||||
- 补充 为什么设计/bin /usr/bin /usr/local/bin
|
||||
- /bin 最基本的,必须有的
|
||||
- /usr/bin 发行版中带的
|
||||
- /usr/local/bin 用户自己安装的
|
||||
- 优先级是先找最后的,然后中间最后前面
|
||||
|
|
@ -0,0 +1,193 @@
|
|||
- 文本为2018年
|
||||
- The First Class: tier-1的conferences, 其实基本上就是AI里面大家比较公认的top conference. 下面同分的按字母序排列.
|
||||
- IJCAI (1+): AI最好的综合性会议, 1969年开始, 每两年开一次, 奇数年开. 因为AI实在太大, 所以虽然每届基本上能录100多篇(现在已经到200多篇了),但分到每个领域就没几篇了,象machine learning、computer vision这么大的领域每次大概也就10篇左右, 所以难度很大. 不过从录用率上来看倒不太低,基本上20%左右, 因为内行人都会掂掂分量, 没希望的就别浪费reviewer的时间了. 最近中国大陆投往国际会议的文章象潮水一样, 而且因为国内很少有能自己把关的研究组, 所以很多会议都在complain说中国的低质量文章严重妨碍了PC的工作效率. 在这种情况下, 估计这几年国际会议的录用率都会降下去. 另外, 以前的IJCAI是没有poster的, 03年开始, 为了减少被误杀的好人, 增加了2页纸的poster.值得一提的是, IJCAI是由貌似一个公司的”IJCAI Inc.”主办的(当然实际上并不是公司, 实际上是个基金会), 每次会议上要发几个奖, 其中最重要的两个是IJCAI Research Excellence Award 和 Computer & Thoughts Award, 前者是终身成就奖, 每次一个人, 基本上是AI的最高奖(有趣的是, 以AI为主业拿图灵奖的6位中, 有2位还没得到这个奖), 后者是奖给35岁以下的青年科学家,每次一个人. 这两个奖的获奖演说是每次IJCAI的一个重头戏.另外, IJCAI 的 PC member 相当于其他会议的area chair, 权力很大, 因为是由PC member去找 reviewer 来审, 而不象一般会议的PC member其实就是 reviewer. 为了制约这种权力, IJCAI的审稿程序是每篇文章分配2位PC member, primary PC member去找3位reviewer, second PC member 找一位.
|
||||
- AAAI (1): 美国人工智能学会AAAI的年会. 是一个很好的会议, 但其档次不稳定, 可以给到1+, 也可以给到1-或者2+, 总的来说我给它”1″. 这是因为它的开法完全受IJCAI制约: 每年开, 但如果这一年的IJCAI在北美举行, 那么就停开. 所以, 偶数年里因为没有IJCAI, 它就是最好的AI综合性会议, 但因为号召力毕竟比IJCAI要小一些, 特别是欧洲人捧AAAI场的比IJCAI少得多(其实亚洲人也是), 所以比IJCAI还是要稍弱一点, 基本上在1和1+之间; 在奇数年, 如果IJCAI不在北美, AAAI自然就变成了比IJCAI低一级的会议(1-或2+), 例如2005年既有IJCAI又有AAAI, 两个会议就进行了协调, 使得IJCAI的录用通知时间比AAAI的deadline早那么几天, 这样IJCAI落选的文章可以投往AAAI.在审稿时IJCAI 的 PC chair也在一直催, 说大家一定要快, 因为AAAI那边一直在担心IJCAI的录用通知出晚了AAAI就麻烦了.
|
||||
- COLT (1): 这是计算学习理论最好的会议, ACM主办, 每年举行. 计算学习理论基本上可以看成理论计算机科学和机器学习的交叉, 所以这个会被一些人看成是理论计算机科学的会而不是AI的会. 我一个朋友用一句话对它进行了精彩的刻画: “一小群数学家在开会”. 因为COLT的领域比较小, 所以每年会议基本上都是那些人. 这里顺便提一件有趣的事, 因为最近国内搞的会议太多太滥, 而且很多会议都是LNCS/LNAI出论文集, LNCS/LNAI基本上已经被搞 臭了, 但很不幸的是, LNCS/LNAI中有一些很好的会议, 例如COLT.
|
||||
- **CVPR** **(1): 计算机视觉和模式识别方面最好的会议之一**, IEEE主办, 每年举行. 虽然题目上有计算机视觉, 但个人认为它的模式识别味道更重一些. 事实上它应该是模式识别最好的会议, 而在计算机视觉方面, 还有ICCV与之相当. IEEE一直有个倾向, 要把会办成”盛会”, 历史上已经有些会被它从quality很好的会办成”盛会”了. CVPR搞不好也要走这条路. 这几年录的文章已经不少了. 最近负责CVPR会议的TC的chair发信说, 对这个community来说, 让好人被误杀比被坏人漏网更糟糕, 所以我们是不是要减少好人被误杀的机会啊? 所以我估计明年或者后年的CVPR就要扩招了.
|
||||
- **ICCV** (1): 介绍CVPR的时候说过了, 计算机视觉方面最好的会之一. IEEE主办, 每年举行.
|
||||
- ICML (1): 机器学习方面最好的会议之一. 现在是IMLS主办, 每年举行. 参见关于NIPS的介绍.
|
||||
- NIPS (1): 神经计算方面最好的会议之一, NIPS主办, 每年举行. 值得注意的是, 这个会每年的举办地都是一样的, 以前是美国丹佛, 现在是加拿大温哥华; 而且它是年底开会,会开完后第2年才出论文集, 也就是说, NIPS’05的论文集是06年出. 会议的名字是”Advances in Neural Information Processing Systems”, 所以, 与ICML\ECML这样的”标准的”机器学习会议不同, NIPS里有相当一部分神经科学的内容, 和机器学习有一定的距离. 但由于会议的主体内容是机器学习, 或者说与机器学习关系紧密, 所以不少人把NIPS看成是机器学习方面最好的会议之一. 这个会议基本上控制在ichael Jordan的徒子徒孙手中, 所以对Jordan系的人来说, 发NIPS并不是难事, 一些未必很强的工作也能发上去, 但对这个圈子之外的人来说, 想发一篇实在很难, 因为留给”外人”的口子很小. 所以对Jordan系以外的人来说, 发NIPS的难度比ICML更大. 换句话说,ICML比较开放, 小圈子的影响不象NIPS那么大, 所以北美和欧洲人都认, 而NIPS则有些人( 特别是一些欧洲人, 包括一些大家)坚决不投稿. 这对会议本身当然并不是好事, 但因为Jordan系很强大, 所以它似乎也不太care. 最近IMLS(国际机器学习学会)改选理事, 有资格提名的人包括近三年在ICML\ECML\COLT发过文章的人, NIPS则被排除在外了. 无论如何, 这是一个非常好的会.
|
||||
- ACL (1-): 计算语言学/自然语言处理方面最好的会议, ACL (Association of Computational Linguistics) 主办, 每年开.
|
||||
- KR (1-): 知识表示和推理方面最好的会议之一, 实际上也是传统AI(即基于逻辑的AI)最好的会议之一. KR Inc.主办, 现在是偶数昕?
|
||||
- SIGIR (1-): 信息检索方面最好的会议, ACM主办, 每年开. 这个会现在小圈子气越来越重. 信息检索应该不算AI, 不过因为这里面用到机器学习越来越多, 最近几年甚至有点机器学习应用会议的味道了, 所以把它也列进来.
|
||||
- SIGKDD (1-): 数据挖掘方面最好的会议, ACM主办, 每年开. 这个会议历史比较短, 毕竟, 与其他领域相比,数据挖掘还只是个小弟弟甚至小侄儿. 在几年前还很难把它列在tier-1里面, 一方面是名声远不及其他的top conference响亮, 另一方面是相对容易被录用. 但现在它被列在tier-1应该是毫无疑问的事情了. 另: 参见sir和lucky的介绍.
|
||||
- UAI (1-): 名字叫”人工智能中的不确定性”, 涉及表示\推理\学习等很多方面, AUAI(Association of UAI) 主办, 每年开.
|
||||
|
||||
- The Second Class:
|
||||
- AAMAS (2+): agent方面最好的会议. 但是现在agent已经是一个一般性的概念, 几乎所有AI有关的会议上都有这方面的内容, 所以AAMAS下降的趋势非常明显.
|
||||
- ECCV (2+): 计算机视觉方面仅次于ICCV的会议, 因为这个领域发展很快, 有可能升级到1-去.
|
||||
- ECML (2+): 机器学习方面仅次于ICML的会议, 欧洲人极力捧场, 一些人认为它已经是1-了. 我保守一点, 仍然把它放在2+. 因为机器学习发展很快, 这个会议的reputation上升非常明显.
|
||||
- ICDM (2+): 数据挖掘方面仅次于SIGKDD的会议, 目前和SDM相当. 这个会只有5年历史, 上升速度之快非常惊人. 几年前ICDM还比不上PAKDD, 现在已经拉开很大距离了.
|
||||
|
||||
- SDM (2+): 数据挖掘方面仅次于SIGKDD的会议, 目前和ICDM相当. SIAM的底子很厚, 但在CS里面的影响比ACM和IEEE还是要小, SDM眼看着要被ICDM超过了, 但至少目前还是相当的.
|
||||
- ICAPS (2): 人工智能规划方面最好的会议, 是由以前的国际和欧洲规划会议合并来的. 因为这个领域逐渐变冷清, 影响比以前已经小了.
|
||||
- ICCBR (2): Case-Based Reasoning方面最好的会议. 因为领域不太大, 而且一直半冷不热, 所以总是停留在2上.
|
||||
- COLLING (2): 计算语言学/自然语言处理方面仅次于ACL的会, 但与ACL的差距比ICCV-ECCV
|
||||
- ICML-ECML大得多.
|
||||
- ECAI (2): 欧洲的人工智能综合型会议, 历史很久, 但因为有IJCAI/AAAI压着, 很难往上升.
|
||||
- ALT (2-): 有点象COLT的tier-2版, 但因为搞计算学习理论的人没多少, 做得好的数来数去就那么些group, 基本上到COLT去了, 所以ALT里面有不少并非计算学习理论的内容.
|
||||
- EMNLP (2-): 计算语言学/自然语言处理方面一个不错的会. 有些人认为与COLLING相当, 但我觉得它还是要弱一点.
|
||||
- ILP (2-): 归纳逻辑程序设计方面最好的会议. 但因为很多其他会议里都有ILP方面的内容, 所以它只能保住2-的位置了.
|
||||
- PKDD (2-): 欧洲的数据挖掘会议, 目前在数据挖掘会议里面排第4. 欧洲人很想把它抬起来, 所以这些年一直和ECML一起捆绑着开, 希望能借ECML把它带起来. 但因为ICDM和SDM, 这已经不太可能了. 所以今年的PKDD和ECML虽然还是一起开, 但已经独立审稿了(以前是可以同时投两个会, 作者可以声明优先被哪个会考虑, 如果ECML中不了还可以被PKDD接受).
|
||||
|
||||
- The Third Class: 列得很不全. 另外, 因为AI的相关会议非常多, 所以能列在tier-3也算不错了, 基本上能进 到所有AI会议中的前30%吧
|
||||
|
||||
- ACCV (3+): 亚洲的计算机视觉会议, 在亚太级别的会议里算很好的了.
|
||||
- DS (3+): 日本人发起的一个接近数据挖掘的会议.
|
||||
- ECIR (3+): 欧洲的信息检索会议, 前几年还只是英国的信息检索会议.
|
||||
- ICTAI (3+): IEEE最主要的人工智能会议, 偏应用, 是被IEEE办烂的一个典型. 以前的quality还是不错的, 但是办得越久声誉反倒越差了, 糟糕的是似乎还在继续下滑, 现在其实3+已经不太呆得住了.
|
||||
- PAKDD (3+): 亚太数据挖掘会议, 目前在数据挖掘会议里排第5.
|
||||
- ICANN (3+): 欧洲的神经网络会议, 从quality来说是神经网络会议中最好的, 但这个领域的人不重视会议,在该领域它的重要性不如IJCNN.
|
||||
- AJCAI (3): 澳大利亚的综合型人工智能会议, 在国家/地区级AI会议中算不错的了.
|
||||
- CAI (3): 加拿大的综合型人工智能会议, 在国家/地区级AI会议中算不错的了.
|
||||
- CEC (3): 进化计算方面最重要的会议之一, 盛会型. IJCNN/CEC/FUZZ-IEEE这三个会议是计算智能或者说软计算方面最重要的会议, 它们经常一起开, 这时就叫WCCI (World Congress on Computational Intelligence). 但这个领域和CS其他分支不太一样, 倒是和其他学科相似, 只重视journal, 不重视会议, 所以录用率经常在85%左右, 所录文章既有
|
||||
- quality非常高的论文, 也有入门新手的习作.
|
||||
- FUZZ-IEEE (3): 模糊方面最重要的会议, 盛会型, 参见CEC的介绍.
|
||||
- GECCO (3): 进化计算方面最重要的会议之一, 与CEC相当,盛会型.
|
||||
- ICASSP (3): 语音方面最重要的会议之一, 这个领域的人也不很care会议.
|
||||
- ICIP (3): 图像处理方面最著名的会议之一, 盛会型.
|
||||
- ICPR (3): 模式识别方面最著名的会议之一, 盛会型.
|
||||
- IEA/AIE (3): 人工智能应用会议. 一般的会议提名优秀论文的通常只有几篇文章, 被提名就已经是很高的荣誉了, 这个会很有趣, 每次都搞1、20篇的优秀论文提名, 专门搞几个session做被提名论文报告, 倒是很热闹.
|
||||
- IJCNN (3): 神经网络方面最重要的会议, 盛会型, 参见CEC的介绍.
|
||||
- IJNLP (3): 计算语言学/自然语言处理方面比较著名的一个会议.
|
||||
- PRICAI (3): 亚太综合型人工智能会议, 虽然历史不算短了, 但因为比它好或者相当的综合型会议太多, 所以很难上升.
|
||||
|
||||
- Combined List:
|
||||
说明: 纯属个人看法, 仅供参考. tier-1的列得较全, tier-2的不太全, tier-3的很不全.
|
||||
同分的按字母序排列. 不很严谨地说, tier-1是可以令人羡慕的, tier-2是可以令人尊敬的
|
||||
,由于AI的相关会议非常多, 所以能列进tier-3的也是不错的
|
||||
|
||||
- tier-1:
|
||||
IJCAI (1+): International Joint Conference on Artificial Intelligence
|
||||
AAAI (1): National Conference on Artificial Intelligence
|
||||
COLT (1): Annual Conference on Computational Learning Theory
|
||||
CVPR (1): IEEE International Conference on Computer Vision and Pattern Recognition
|
||||
ICCV (1): IEEE International Conference on Computer Vision
|
||||
ICML (1): International Conference on Machine Learning
|
||||
NIPS (1): Annual Conference on Neural Information Processing Systems
|
||||
ACL (1-): Annual Meeting of the Association for Computational Linguistics
|
||||
KR (1-): International Conference on Principles of Knowledge Representation and Reasoning
|
||||
SIGIR (1-): Annual International ACM SIGIR Conference on Research and Development in Information Retrieval
|
||||
SIGKDD (1-): ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
|
||||
UAI (1-): International Conference on Uncertainty in Artificial Intelligence
|
||||
|
||||
- tier-2:
|
||||
AAMAS (2+): International Joint Conference on Autonomous Agents and Multiagent Systems
|
||||
ECCV (2+): European Conference on Computer Vision
|
||||
ECML (2+): European Conference on Machine Learning
|
||||
ICDM (2+): IEEE International Conference on Data Mining
|
||||
SDM (2+): SIAM International Conference on Data Mining
|
||||
ICAPS (2): International Conference on Automated Planning and Scheduling
|
||||
ICCBR (2): International Conference on Case-Based Reasoning
|
||||
COLLING (2): International Conference on Computational Linguistics
|
||||
ECAI (2): European Conference on Artificial Intelligence
|
||||
ALT (2-): International Conference on Algorithmic Learning Theory
|
||||
EMNLP (2-): Conference on Empirical Methods in Natural Language Processing
|
||||
ILP (2-): International Conference on Inductive Logic Programming
|
||||
PKDD (2-): European Conference on Principles and Practice of Knowledge Discovery in Databases
|
||||
|
||||
- tier-3:
|
||||
ACCV (3+): Asian Conference on Computer Vision
|
||||
DS (3+): International Conference on Discovery Science
|
||||
ECIR (3+): European Conference on IR Research
|
||||
ICTAI (3+): IEEE International Conference on Tools with Artificial Intelligence
|
||||
PAKDD (3+): Pacific-Asia Conference on Knowledge Discovery and Data Mining
|
||||
ICANN (3+): International Conference on Artificial Neural Networks
|
||||
AJCAI (3): Australian Joint Conference on Artificial Intelligence
|
||||
CAI (3): Canadian Conference on Artificial Intelligence
|
||||
CEC (3): IEEE Congress on Evolutionary Computation
|
||||
FUZZ-IEEE (3): IEEE International Conference on Fu Systems
|
||||
GECCO (3): Genetic and Evolutionary Computation Conference
|
||||
ICASSP (3): International Conference on Acoustics, Speech, and Signal Processing
|
||||
ICIP (3): International Conference on Image Processing
|
||||
ICPR (3): International Conference on Pattern Recognition
|
||||
IEA/AIE (3): International Conference on Industrial and Engineering
|
||||
Applications of Artificial Intelligence and Expert Systems
|
||||
IJCNN (3): International Joint Conference on Neural Networks
|
||||
IJNLP (3): International Joint Conference on Natural Language Processing
|
||||
|
||||
|
||||
ACL会议
|
||||
|
||||
ACL会议(Annual Meeting of the Association for Computational Linguistics)是自然语言处理与计算语言学领域最高级别的学术会议,由计算语言学协会主办,每年一届。
|
||||
涉及
|
||||
对话(Dialogue)
|
||||
篇章(Discourse)
|
||||
评测( Eval)
|
||||
信息抽取( IE)
|
||||
信息检索( IR)
|
||||
语言生成(LanguageGen)
|
||||
语言资源(LanguageRes)
|
||||
机器翻译(MT)
|
||||
多模态(Multimodal)
|
||||
音韵学/ 形态学( Phon/ Morph)
|
||||
自动问答(QA)
|
||||
语义(Semantics)
|
||||
情感(Sentiment)
|
||||
语音(Speech)
|
||||
统计机器学习(Stat ML)
|
||||
文摘(Summarisation)
|
||||
句法(Syntax)
|
||||
等多个方面
|
||||
|
||||
|
||||
自然语言处理及计算语言学常见缩略语
|
||||
|
||||
ACL = Association for Computational Linguistics(计算语言学协会)
|
||||
AFNLP = Asian Federation of Natural Language Processing(亚洲自然语言处理联盟)
|
||||
AI = Artificial Intelligence(人工智能)
|
||||
ALPAC = Automated Language Processing Advisory Committee(语言自动处理咨询委员会)
|
||||
ASR = Automatic Speech Recognition(自动语音识别)
|
||||
CAT = Computer Assisted/Aided Translation(计算机辅助翻译)
|
||||
CBC = Clustering by Committee
|
||||
CCG = Combinatory Categorial Grammar(组合范畴语法)
|
||||
CICLing = International Conference on Intelligent text processing and Computational Linguistics(国际智能文本处理与计算语言学大会)
|
||||
CL = Computational Linguistics(计算语言学)
|
||||
COBUILD = Collins Birmingham University International Language Database(柯林斯伯明翰大学国际语言数据库)
|
||||
COLING = International Conference on Computational Linguistics(国际计算语言学大会)
|
||||
CRF = Conditional Random Fields(条件随机场)
|
||||
DRS = Discourse Representation Structure(篇章表述结构)
|
||||
DRT = Discourse Representation Theory(篇章表述理论)
|
||||
EACL = European chapter of the Association for Computational Linguistics
|
||||
EBMT = Example-based machine translation(基于实例的机器翻译)
|
||||
EM = Expectation Maximization(期望最大化)
|
||||
FAHQMT = Fully Automated High-Quality Machine Translation(全自动高质量机器翻译)
|
||||
FOL = First Order Logic(一阶逻辑)
|
||||
HAMT = Human Assisted/Aided Machine Translation(人工辅助机器翻译)
|
||||
HLT = Human Language Technologies(人类语言技术)
|
||||
HMM = Hidden Markov Model(隐马尔科夫模型)
|
||||
HPSG = Head-Driven Phrase Structure Grammar(中心语驱动短语结构语法)
|
||||
IE = Information Extraction(信息抽取)
|
||||
IR = Information Retrieval(信息检索)
|
||||
IST = Information Society Technologies(信息社会技术)
|
||||
KR = Knowledge Representation(知识表示)
|
||||
LFG = Lexical Functional Grammar(词汇功能语法)
|
||||
LSA = Latent Semantic Analysis(潜在语义分析); Linguistics Society of America(美国语言学学会)
|
||||
LSI = Latent Semantic Indexing(潜在语义索引)
|
||||
MAHT = Machine Assised/Aided Human Translation(计算机辅助人工翻译)
|
||||
ME = Maximum Entropy(最大熵)
|
||||
MI = Mutual Information(互信息)
|
||||
ML = Machine Learning(机器学习)
|
||||
MRD = Machine-Readable Dictionary(机读词典)
|
||||
MT = Mechanical Translation/Machine Translation (机器翻译)
|
||||
NAACL = North American chapter of the Association for Computational Linguistics
|
||||
NE = Named Entity(命名实体)
|
||||
NEALT = Northern European Association for Language Technology
|
||||
NER = Named Entity Recognition(命名实体识别)
|
||||
NLG = Natural Language Generation(自然语言生成)
|
||||
NLP = Natural Language Processing(自然语言处理)
|
||||
NLU = Natural Language Understanding(自然语言理解)
|
||||
NML = National Museum of Language
|
||||
PLSA = Probabilistic Latent Semantic Analysis(概率潜在语义分析)
|
||||
PMI = Pointwise Mutual Information(点间互信息)
|
||||
POS = Part of Speech(词性)
|
||||
RTE = Recognising Textual Entailment
|
||||
SLT = Spoken Language Translation(口语翻译)
|
||||
SVM = Support Vector Machine(支持向量机)
|
||||
TAG = Tree-Adjoining Grammar(树邻接语法)
|
||||
TINLAP = Theoretical Issues in Natural Language Processing
|
||||
TLA = Three-letter acronym(三字母缩略语)
|
||||
TMI = Theoretical and Methodological Issues (in Machine Translation)
|
||||
TREC = The Text REtrieval Conference(文本检索会议)
|
||||
VSM = Vector Space Model(向量空间模型)
|
||||
WSD = Word Sense Disambiguation(词义消歧)
|
||||
|
|
@ -0,0 +1,319 @@
|
|||
**作者:宋天龙
|
||||
链接:https://www.zhihu.com/question/63383992/answer/222718972
|
||||
来源:知乎
|
||||
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。**
|
||||
|
||||
|
||||
|
||||
|
||||
## 1. 综合数据集
|
||||
|
||||
**UCI数据集**
|
||||
|
||||
UCI数据集中包括了众多用于监督式和非监督式学习的数据集,数量大概400多个,其中很多数据集在其他众多数据工具中被反复引用,例如Iris、Wine、Adult、Car
|
||||
Evaluation、Forest Fires等。
|
||||
|
||||
每个数据集中都有关于数据实例数、数据产生领域、值域分布、特征数量、数据产生时间、模型方向、是否有缺失值等详细数据介绍,可用于分类、回归、聚类、时间序列、推荐系统等。
|
||||
|
||||
推荐度:★★★,推荐应用方向:监督式、非监督式机器学习,数据挖掘
|
||||
|
||||
介绍和下载地址:[http://archive.ics.uci.edu/ml/](https://link.zhihu.com/?target=http%3A//archive.ics.uci.edu/ml/)
|
||||
|
||||
**UCI KDD数据集**
|
||||
|
||||
UCI KDD(知识发现)是数据挖掘和可视化的研究项目,专注于大型数据收集中的实体事件关系。它是涉及几所大学的更广泛的KDD项目的一部分,UCI始于2002年10月。
|
||||
|
||||
推荐度:★★,推荐应用方向:监督式、非监督式机器学习
|
||||
|
||||
介绍地址:[http://kdd.ics.uci.edu/](https://link.zhihu.com/?target=http%3A//kdd.ics.uci.edu/)
|
||||
|
||||
下载地址:[http://kdd.ics.uci.edu/databases/](https://link.zhihu.com/?target=http%3A//kdd.ics.uci.edu/databases/)
|
||||
|
||||
**雅虎Webscope**
|
||||
|
||||
雅虎Webscope用于为学者和其他科学家在非商业用途中使用。所有数据集已经过审查,以符合雅虎的数据保护标准,包括严格的隐私控制。数据集中包含了多个主题数据集:广告和市场营销、自然语言数据、科学数据、图形和社会化数据、图像数据等7个主题。需要注意的是:数据集只适用于同意数据共享协议的教师和大学研究人员的在学术上使用。
|
||||
|
||||
推荐度:★★★,推荐应用方向:监督式、非监督式机器学习、深度学习、自然语言理解等
|
||||
|
||||
介绍和下载地址:[https://webscope.sandbox.yahoo.com/](https://link.zhihu.com/?target=https%3A//webscope.sandbox.yahoo.com/)
|
||||
|
||||
**AWS 公开数据集**
|
||||
|
||||
亚马逊提供的数据集涵盖气候、红外图像、卫星遥感、人类微生物、日本人口普查、公共电子邮件档案、歌曲、材料安全、谷歌图书语料库、石油等非常多的主题数据,并且这些数据可直接集成到AWS进行数据挖掘和学习。
|
||||
|
||||
推荐度:★★★,推荐应用方向:监督式、非监督式机器学习、深度学习、神经网络、自然语言理解等
|
||||
|
||||
介绍和下载地址:[https://aws.amazon.com/cn/datasets/](https://link.zhihu.com/?target=https%3A//aws.amazon.com/cn/datasets/)
|
||||
|
||||
**斯坦福网络数据集**
|
||||
|
||||
斯坦福网络分析平台(SNAP)是一种用于分析和操纵大型网络的通用高性能系统,其本身使用的网络相关数据也对外开放,包括设计、社区、通信、网络图、互联网、道路、维基百度网络、在线社区和评论等不同主题,可用于分析大型社会和信息网络方面的研究成果。
|
||||
|
||||
推荐度:★★★,推荐应用方向:神经网络
|
||||
|
||||
介绍和下载地址:[http://snap.stanford.edu/data/index.html](https://link.zhihu.com/?target=http%3A//snap.stanford.edu/data/index.html)
|
||||
|
||||
**KONECT网络数据集**
|
||||
|
||||
KONECT数据集是一个大型网络数据集的项目,在科布伦茨-兰道大学网络科学与技术研究所的网络科学和相关领域进行研究。KONECT包含数百种各种类型的网络数据集,包括有向、无向、二分、加权、未加权、签名和评级的网络。 KONECT的网络覆盖了许多不同领域,如社交网络,超链接网络、作者网络、物理网络、交互网络和通信网络等。
|
||||
|
||||
推荐度:★★★,推荐应用方向:神经网络
|
||||
|
||||
介绍和下载地址:[http://konect.uni-koblenz.de/](https://link.zhihu.com/?target=http%3A//konect.uni-koblenz.de/)
|
||||
|
||||
## 2. 图像和视频数据集
|
||||
|
||||
**MNIST数据集**
|
||||
|
||||
机器学习领域内用于手写字识别的数据集,数据集中包含6个万训练集、10000个示例测试集。,每个样本图像的宽高为28*28。这些数据集的大小已经归一化,并且形成固定大小,因此预处理工作基本已经完成。在机器学习中,主流的机器学习工具(包括sklearn)很多都使用该数据集作为入门级别的介绍和应用。
|
||||
|
||||
推荐度:★★★,推荐应用方向:机器学习入门
|
||||
|
||||
介绍和下载地址:[http://yann.lecun.com/exdb/mnist/](https://link.zhihu.com/?target=http%3A//yann.lecun.com/exdb/mnist/)
|
||||
|
||||
**CIFAR 10 & CIFAR 100数据集**
|
||||
|
||||
CIFAR-10数据集由10个类别的60000 32x32彩色图像组成,每个类别有6000张图像。 有50000个训练图像和10000个测试图像。数据集的类别涵盖航空、车辆、鸟类、猫类、狗类、狐狸类、马类、船类、卡车等日常生活类别,可用于计算机视觉相关方向。
|
||||
|
||||
推荐度:★★★,推荐应用方向:图像处理和图像识别
|
||||
|
||||
介绍和下载地址:[http://www.cs.toronto.edu/~kriz/cifar.html/](https://link.zhihu.com/?target=http%3A//www.cs.toronto.edu/%7Ekriz/cifar.html/)
|
||||
|
||||
**谷歌Open Images Dataset图像数据集**
|
||||
|
||||
其中包括大约9百万标注图片、横跨6000个类别标签,平均每个图像拥有8个标签。该数据集的标签涵盖比拥有1000个类别标签的ImageNet具体更多的现实实体,可用于计算机视觉方向的训练。
|
||||
|
||||
推荐度:★★★,推荐应用方向:图像处理和图像识别
|
||||
|
||||
介绍地址:[https://research.googleblog.com/2016/09/introducing-open-images-dataset.html](https://link.zhihu.com/?target=https%3A//research.googleblog.com/2016/09/introducing-open-images-dataset.html)
|
||||
|
||||
下载地址:[https://github.com/openimages/dataset](https://link.zhihu.com/?target=https%3A//github.com/openimages/dataset)
|
||||
|
||||
**ImageNet数据集**
|
||||
|
||||
ImageNet数据集是目前深度学习图像领域应用得非常多的一个领域,该数据集有1000多个图像,涵盖图像分类、定位、检测等应用方向。Imagenet数据集文档详细,有专门的团队维护,在计算机视觉领域研究论文中应用非常广,几乎成为了目前深度学习图像领域算法性能检验的“标准”数据集。很多大型科技公司都会参加ImageNet图像识别大赛,包括百度、谷歌、微软等。
|
||||
|
||||
推荐度:★★★,推荐应用方向:图像识别
|
||||
|
||||
介绍和下载地址:[http://www.image-net.org/](https://link.zhihu.com/?target=http%3A//www.image-net.org/)
|
||||
|
||||
**Tiny Images Dataset**
|
||||
|
||||
该数据集由79302017张图像组成,每张图像为32x32彩色图像。 该数据以二进制文件的形式存储,大约有400Gb图像。
|
||||
|
||||
推荐度:★★,推荐应用方向:图像识别
|
||||
|
||||
介绍和下载地址:[http://horatio.cs.nyu.edu/mit/tiny/data/index.html](https://link.zhihu.com/?target=http%3A//horatio.cs.nyu.edu/mit/tiny/data/index.html)
|
||||
|
||||
**CoPhIR**
|
||||
|
||||
CoPhIR是从Flickr中采集的大概1.06亿个图像数据集,图像中不仅包含了图表本身的数据,例如位置、标题、GPS、标签、评论等,还可提取出颜色模式、颜色布局、边缘直方图、均匀纹理等数据。
|
||||
|
||||
推荐度:★★,推荐应用方向:图像识别
|
||||
|
||||
介绍和下载地址:[http://cophir.isti.cnr.it/whatis.html](https://link.zhihu.com/?target=http%3A//cophir.isti.cnr.it/whatis.html)
|
||||
|
||||
**LSUN数据集**
|
||||
|
||||
国外的PASCAL
|
||||
VOC和ImageNet ILSVRC比赛使用的数据集,数据领域包括卧室、冰箱、教师、厨房、起居室、酒店等多个主题。
|
||||
|
||||
推荐度:★★,推荐应用方向:图像识别
|
||||
|
||||
介绍和下载地址:[http://lsun.cs.princeton.edu](https://link.zhihu.com/?target=http%3A//lsun.cs.princeton.edu)
|
||||
|
||||
**Labeled Faces in the Wild数据集**
|
||||
|
||||
该数据集是用于研究无约束面部识别问题的面部照片数据库。数据集包含从网络收集的13000多张图像。每张脸都贴上了所画的人的名字,图片中的1680人在数据集中有两个或更多不同的照片。
|
||||
|
||||
推荐度:★★,推荐应用方向:人脸识别
|
||||
|
||||
介绍和下载地址:[http://vis-www.cs.umass.edu/lfw/](https://link.zhihu.com/?target=http%3A//vis-www.cs.umass.edu/lfw/)
|
||||
|
||||
**SVHN**
|
||||
|
||||
SVHN数据来源于 Google 街景视图中房屋信息,它是一个真实世界的图像数据集,用于开发机器学习和对象识别算法,对数据预处理和格式化的要求最低。它跟MNIST相似,但是包含更多数量级的标签数据(超过60万个数字图像),并且来源更加多样,用来识别自然场景图像中的数字。
|
||||
|
||||
推荐度:★★,推荐应用方向:机器学习、图像识别
|
||||
|
||||
介绍和下载地址:[http://ufldl.stanford.edu/housenumbers/](https://link.zhihu.com/?target=http%3A//ufldl.stanford.edu/housenumbers/)
|
||||
|
||||
**COCO**
|
||||
|
||||
COCO(Common Objects in Context)是一个新的图像识别、分割和图像语义数据集,由微软赞助,图像中不仅有标注类别、位置信息,还有对图像的语义文本描述。COCO数据集的开源使得近两、三年来图像分割语义理解取得了巨大的进展,也几乎成为了图像语义理解算法性能评价的“标准”数据集。
|
||||
|
||||
推荐度:★★★,推荐应用方向:图像识别、图像语义理解
|
||||
|
||||
介绍和下载地址:[http://mscoco.org/](https://link.zhihu.com/?target=http%3A//mscoco.org/)
|
||||
|
||||
**谷歌YouTube-8M**
|
||||
|
||||
YouTube-8M一个大型的多样性标注的视频数据集,目前拥有700万的YouTube视频链接、45万小时视频时长、3.2亿视频/音频特征、4716个分类、平均每个视频拥有3个标签。
|
||||
|
||||
推荐度:★★★,推荐应用方向:视频理解、表示学习(representation learning)、嘈杂数据建模、转移学习(transfer learning)和视频域适配方法(domain
|
||||
adaptation approaches)
|
||||
|
||||
数据集介绍和下载地址:[https://research.google.com/youtube8m/](https://link.zhihu.com/?target=https%3A//research.google.com/youtube8m/)。
|
||||
|
||||
**Udacity开源的车辆行使视频数据集**
|
||||
|
||||
数据集大概有223G,主要是有关车辆驾驶的数据,其中除了车辆拍摄的图像以外,还包括车辆本身的属性和参数信息,例如经纬度、制动器、油门、转向度、转速等。这些数据可用于车辆自动驾驶方向的模型训练和学习。
|
||||
|
||||
推荐度:★★★,推荐应用方向:自动驾驶
|
||||
|
||||
介绍和下载地址:[https://github.com/udacity/self-driving-car](https://link.zhihu.com/?target=https%3A//github.com/udacity/self-driving-car)
|
||||
|
||||
**牛津RobotCar视频数据集**
|
||||
|
||||
RobotCar数据集包含时间范围超过1年,测试超过100次的相同路线的驾驶数据。数据集采集了天气、交通、行人、建筑和道路施工等不同组合的数据。
|
||||
|
||||
推荐度:★★★,推荐应用方向:自动驾驶
|
||||
|
||||
介绍和下载地址:[http://robotcar-dataset.robots.ox.ac.uk/](https://link.zhihu.com/?target=http%3A//robotcar-dataset.robots.ox.ac.uk/)
|
||||
|
||||
**Udacity开源的自然场景短视频数据集**
|
||||
|
||||
数据集大概为9T,由3500万个视频剪辑组成,每个视频为短视频(32帧),大约1秒左右的时长。
|
||||
|
||||
推荐度:★★★,推荐应用方向:目标跟踪、视频目标识别
|
||||
|
||||
介绍和下载地址:[http://web.mit.edu/vondrick/tinyvideo/#data](https://link.zhihu.com/?target=http%3A//web.mit.edu/vondrick/tinyvideo/%23data)
|
||||
|
||||
## 3. 自然语言数据集
|
||||
|
||||
**MS MARCO**
|
||||
|
||||
MS MARCO是一种新的大规模阅读理解和问答数据集。 在MS MARCO中,所有问题都是从真正的匿名用户查询中抽取的。使用先进的Bing搜索引擎版本,从实际的Web文档中提取数据集中的答案的上下文段落。
|
||||
|
||||
推荐度:★★★,推荐应用方向:自然语言理解、智能问答
|
||||
|
||||
介绍和下载地址:[http://www.msmarco.org/](https://link.zhihu.com/?target=http%3A//www.msmarco.org/)
|
||||
|
||||
**Question Pairs**
|
||||
|
||||
第一个来源于
|
||||
Quora 的包含重复/语义相似性标签的数据集。数据集由超过40万行的潜在问题的问答组成。每行数据包含问题ID、问题全文以及指示该行是否真正包含重复对的二进制值。
|
||||
|
||||
推荐度:★★★,推荐应用方向:自然语言理解、智能问答
|
||||
|
||||
介绍和下载地址:[https://data.quora.com/First-Quora-Dataset-Release-Question-Pairs](https://link.zhihu.com/?target=https%3A//data.quora.com/First-Quora-Dataset-Release-Question-Pairs)
|
||||
|
||||
**SQuAD**
|
||||
|
||||
斯坦福问答回答数据集(SQuAD)是一个新的阅读理解数据集,从维基百科中提炼出的问题组成,每个问题的答案都是相应段落的一段文本。在500多篇文章中有超过10万个问答对。
|
||||
|
||||
推荐度:★★★,推荐应用方向:文本挖掘、自然语言理解、智能问答
|
||||
|
||||
介绍和下载地址:[https://rajpurkar.github.io/SQuAD-explorer/](https://link.zhihu.com/?target=https%3A//rajpurkar.github.io/SQuAD-explorer/)
|
||||
|
||||
**Maluuba NewsQA**
|
||||
|
||||
Maluuba的NewsQA数据集的目的是帮助研究团队建立能够回答需要人为理解和推理技能的问题的算法。它包含了从DeepMind问答数据集中的CNN文章中抽取了120K个常见问题。
|
||||
|
||||
推荐度:★★,推荐应用方向:文本挖掘、自然语言理解、智能问答
|
||||
|
||||
介绍地址:[https://datasets.maluuba.com/NewsQA](https://link.zhihu.com/?target=https%3A//datasets.maluuba.com/NewsQA)
|
||||
|
||||
下载地址:[https://github.com/Maluuba/newsqa](https://link.zhihu.com/?target=https%3A//github.com/Maluuba/newsqa)
|
||||
|
||||
**1 Billion Word Language Model Benchmark**
|
||||
|
||||
这是一个大型、通用的语言建模数据集,该项目的目的是提供语言建模实验的标准培训和测试,常用于如 word2vec 或 Glove 的分布式词语表征。
|
||||
|
||||
推荐度:★★,推荐应用方向:文本挖掘、自然语言理解
|
||||
|
||||
介绍和下载地址:[http://www.statmt.org/lm-benchmark/](https://link.zhihu.com/?target=http%3A//www.statmt.org/lm-benchmark/)
|
||||
|
||||
**Maluuba Datasets**
|
||||
|
||||
这是一个用于自然语言理解研究的复杂的人工数据集,主要包括NewsQA和Frames。它主要用于机器阅读理解、面向对象的对话系统、对话界面和加强学习。
|
||||
|
||||
推荐度:★★,推荐应用方向:自然语言理解、智能问答
|
||||
|
||||
介绍和下载地址:[https://datasets.maluuba.com/](https://link.zhihu.com/?target=https%3A//datasets.maluuba.com/)
|
||||
|
||||
**Common Crawl**
|
||||
|
||||
Common Crawl包含了超过7年的网络爬虫数据集,拥有PB级规模,常用于学习词嵌入。
|
||||
|
||||
推荐度:★★,推荐应用方向:文本挖掘、自然语言理解
|
||||
|
||||
介绍和下载地址:[http://commoncrawl.org/the-data/](https://link.zhihu.com/?target=http%3A//commoncrawl.org/the-data/)
|
||||
|
||||
**20 Newsgroups**
|
||||
|
||||
该数据集包含大约20000个新闻组文档,在20个不同的新闻组中平均分配,是一个文本分类的经典数据集,它是机器学习技术的文本应用中的实验的流行数据集,如文本分类和文本聚类。
|
||||
|
||||
推荐度:★★,推荐应用方向:文本挖掘
|
||||
|
||||
介绍和下载地址:[http://qwone.com/~jason/20Newsgroups/](https://link.zhihu.com/?target=http%3A//qwone.com/%7Ejason/20Newsgroups/)
|
||||
|
||||
## 4. 音频数据集
|
||||
|
||||
**大型音乐分析数据集FMA**
|
||||
|
||||
该数据集是免费音乐存档(FMA)的转储,这是一个高质量的合法音频下载的互动库。这些数据集中包含歌曲名称、音乐类型、曲目计数等信息,共计689种歌曲和68种类型。该数据集可用于音乐分析。
|
||||
|
||||
推荐度:★★★,推荐应用方向:音乐分析挖掘
|
||||
|
||||
介绍和下载地址:[https://lts2.epfl.ch/datasets/fma/](https://link.zhihu.com/?target=https%3A//lts2.epfl.ch/datasets/fma/)
|
||||
|
||||
**音频数据集AudioSet**
|
||||
|
||||
谷歌发布的大规模一品数据集,AudioSet 包括 632 个音频事件类的扩展类目和从YouTube视频绘制的 2084320 个人类标记的10秒声音剪辑的集合。类目被指定为事件类别的分层图,覆盖广泛的人类和动物声音,乐器和风格以及常见的日常环境声音。
|
||||
|
||||
推荐度:★★★,推荐应用方向:音乐、人声、车辆、乐器、室内等自然和人物声音分析挖掘
|
||||
|
||||
介绍和下载地址:[https://github.com/audioset/ontology](https://link.zhihu.com/?target=https%3A//github.com/audioset/ontology)
|
||||
|
||||
**2000 HUB5 English Evaluation Transcripts**
|
||||
|
||||
该数据集由NIST(国家标准与技术研究院)2000年发起的HUB5评估中使用的40个英语电话对话的成绩单组成,其仅包含英语的语音数据集,百度最近的论文《深度语音:扩展端对端语音识别》使用的是这个数据集。
|
||||
|
||||
推荐度:★★★,推荐应用方向:音乐、人声、车辆、乐器、室内等自然和人物声音识别
|
||||
|
||||
介绍和下载地址:[https://catalog.ldc.upenn.edu/LDC2002T43](https://link.zhihu.com/?target=https%3A//catalog.ldc.upenn.edu/LDC2002T43)
|
||||
|
||||
**LibriSpeech**
|
||||
|
||||
该数据集为包含文本和语音的有声读物数据集,由Vassil Panayotov编写的大约1000小时的16kHz读取英语演讲的语料库。数据来源于LibriVox项目的阅读有声读物,并经过细致的细分和一致。
|
||||
|
||||
推荐度:★★,推荐应用方向:自然语音理解和分析挖掘
|
||||
|
||||
介绍和下载地址:[http://www.openslr.org/12/](https://link.zhihu.com/?target=http%3A//www.openslr.org/12/)
|
||||
|
||||
**VoxForge**
|
||||
|
||||
该数据集是带口音的语音清洁数据集,对测试模型在不同重音或语调下的鲁棒性非常有用。
|
||||
|
||||
推荐度:★★,推荐应用方向:语音识别
|
||||
|
||||
介绍和下载地址:[http://www.voxforge.org/](https://link.zhihu.com/?target=http%3A//www.voxforge.org/)
|
||||
|
||||
**TIMIT**
|
||||
|
||||
这是一份英文语音识别数据集,包含630个扬声器的宽带录音,八个主要方言的美式英语,每个阅读十个语音丰富的句子。TIMIT语料库包括时间对齐的正字法,语音和单词转录以及每个话语的16位,16kHz语音波形文件。
|
||||
|
||||
推荐度:★★,推荐应用方向:语音识别
|
||||
|
||||
介绍和下载地址:[https://catalog.ldc.upenn.edu/LDC93S1](https://link.zhihu.com/?target=https%3A//catalog.ldc.upenn.edu/LDC93S1)
|
||||
|
||||
**CHIME**
|
||||
|
||||
这份语音一份包含环境噪音的用于语音识别挑战赛(CHiME Speech Separation and Recognition Challenge)的数据集。该数据集包含了训练集、开发机、测试集三部分,每份里面包括了多个扬声器在不同噪音环境下的数据。
|
||||
|
||||
推荐度:★★★,推荐应用方向:语音识别
|
||||
|
||||
介绍和下载地址:[http://spandh.dcs.shef.ac.uk/chime_challenge/index.html](https://link.zhihu.com/?target=http%3A//spandh.dcs.shef.ac.uk/chime_challenge/index.html)
|
||||
|
||||
**TED-LIUM**
|
||||
|
||||
TED Talk 的音频数据集,包含1495个录音和音频会议、159848条发音词典和部分WMT12公开的语料库。
|
||||
|
||||
推荐度:★★★,推荐应用方向:语音识别
|
||||
|
||||
介绍和下载地址:[http://www-lium.univ-lemans.fr/en/content/ted-lium-corpus](https://link.zhihu.com/?target=http%3A//www-lium.univ-lemans.fr/en/content/ted-lium-corpus)
|
||||
|
||||
|
||||
|
||||
除了上述公开数据集外,不要忘记大多数机器学习和数据挖掘工具本身也附带有datasets资源,甚至像sklearn还提供了生成模拟数据的功能(实际上专业的数据工具都有很多),请见sklearn中的datasets方法。
|
||||
Loading…
Reference in New Issue