vault backup: 2025-07-23 09:47:11
This commit is contained in:
parent
a6a40e02d1
commit
b8ca4f5969
|
|
@ -1,15 +1,45 @@
|
||||||
|
|
||||||
- dvfs
|
- 7月22日
|
||||||
|
- 所有的单板
|
||||||
|
- dvt1 没问题
|
||||||
|
- dvt2 没问题
|
||||||
|
- evt 没问题
|
||||||
|
- dvt3 赵亚琳之前的单板 出了一个052 198 isp
|
||||||
|
- dvt4 产线回来的 ddr
|
||||||
|
- 才仕民交接 21的osc是否做trim
|
||||||
|
- 出厂的trim 陈千里确认电路信息
|
||||||
|
- 校准
|
||||||
|
- 常温
|
||||||
|
- 高低温 环境也需要切换到高低温进行测试
|
||||||
|
- 顺带的pvt信息
|
||||||
|
- psensor不需要校准
|
||||||
|
- Vsensor也可能不需要校准
|
||||||
|
- Tsensor常温校准
|
||||||
|
- 歌尔出压测版本
|
||||||
|
- 现象收集
|
||||||
|
- isp 198 0.52 死机 但是其它的都能跑完 不好说有没有纹波
|
||||||
|
- bus的版本 198->118 052/192的组合如何
|
||||||
|
- aisp+isp ? 突发的irdrop
|
||||||
|
- 调压代码整理!
|
||||||
|
- v2.8
|
||||||
|
- v2.7 主要是055的处理 下午设计出流程图
|
||||||
|
- cpu什么问题
|
||||||
|
- 杭州单板调查
|
||||||
|
- 7月19日
|
||||||
|
- 单板对比
|
||||||
|
- dvt1 / evt2
|
||||||
|
-
|
||||||
|
- dvfs
|
||||||
- 2.7
|
- 2.7
|
||||||
- 合入mapi中factory模式
|
- 合入mapi中factory模式 ok
|
||||||
- 合入pvt数据
|
- 合入pvt数据
|
||||||
- 合入静态模式? 外加一个参数(sample还是什么),表示运行完之后底层更新数据
|
- 合入静态模式? 外加一个参数(sample还是什么),表示运行完之后底层更新数据 (temp calibrated)
|
||||||
- DVFS目前的坑
|
- DVFS目前的坑
|
||||||
- 2.7
|
- 2.7
|
||||||
- 增加了060限制, 但是不能做产测了 需要mapi也修改 ----> 去掉限制,改bus频率
|
- 增加了060限制, 但是不能做产测了 需要mapi也修改 ----> 去掉限制,改bus频率
|
||||||
- 2.8
|
- 2.8
|
||||||
- 降不到055了
|
- 降不到055了
|
||||||
- 赵亚琳
|
- 赵亚琳
|
||||||
- 自己单块evt1 几十次之后
|
- 自己单块evt1 几十次之后
|
||||||
- evt2 几百次出了一次 五六十次出了一次 28012
|
- evt2 几百次出了一次 五六十次出了一次 28012
|
||||||
- dvt1整体不良 5%
|
- dvt1整体不良 5%
|
||||||
|
|
@ -93,9 +123,9 @@ K77 新eco 2510 2515
|
||||||
- 整理dvfs问题
|
- 整理dvfs问题
|
||||||
- 编码
|
- 编码
|
||||||
- **dvfs未合入内容**
|
- **dvfs未合入内容**
|
||||||
- 无校准信息的0.6v
|
- 无校准信息的0.6v 只合2.7 2.8没合
|
||||||
- system: dvfs_0618_060_protect
|
- system: dvfs_0618_060_prohibit
|
||||||
- mapi : dvfs_0618_060_protect
|
- mapi : dvfs_0618_060_prohibit
|
||||||
- 固定电压的sample_factory
|
- 固定电压的sample_factory
|
||||||
- project/sdk-v2.8-static-sample-factory
|
- project/sdk-v2.8-static-sample-factory
|
||||||
|
|
||||||
|
|
|
||||||
|
|
@ -0,0 +1,65 @@
|
||||||
|
> 工艺角(Process Corner)是集成电路(IC)设计中的核心概念,用于量化**芯片制造过程中的工艺波动对晶体管性能的影响**。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
1.工艺角的本质
|
||||||
|
|
||||||
|
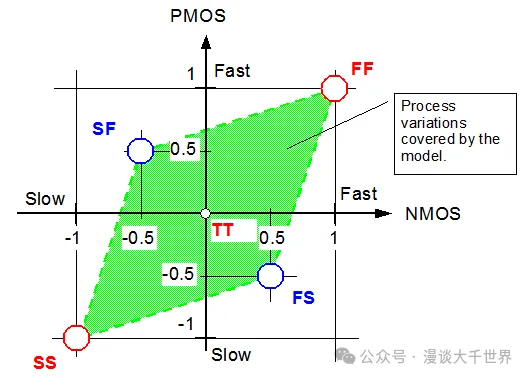
芯片制造存在不可避免的物理波动(如光刻偏差、掺杂不均匀),导致同一晶圆上不同区域的晶体管参数(阈值电压 )、载流子迁移率 )、栅氧厚度 ) 等)偏离设计值。
|
||||||
|
|
||||||
|
工艺角通过组合 **NMOS** 和 **PMOS** 晶体管的 **“快”(Fast)** 与 **“慢”(Slow)** 两种极端状态,模拟性能边界。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
> **关键公式**:晶体管驱动电流
|
||||||
|
>
|
||||||
|
> **“快”晶体管**: 低 + 高 → 大 → 开关速度快
|
||||||
|
>
|
||||||
|
> **“慢”晶体管**: 高 + 低 → 小 → 开关速度慢
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
2.工艺角分类
|
||||||
|
|
||||||
|
|**缩写**|**NMOS状态**|**PMOS状态**|**芯片特性**|**核心应用场景**|
|
||||||
|
|---|---|---|---|---|
|
||||||
|
|**TT**|典型 (Typ)|典型 (Typ)|设计中心值|功能验证、基准性能评估|
|
||||||
|
|**FF**|快 (Fast)|快 (Fast)|**速度最快,功耗最大**|最大频率(Fmax)、最坏功耗分析|
|
||||||
|
|**SS**|慢 (Slow)|慢 (Slow)|**速度最慢,功耗最小**|建立时间(Setup)验证、漏电流分析|
|
||||||
|
|**FS**|快 (Fast)|慢 (Slow)|NMOS快 + PMOS慢|对PMOS敏感路径的保持时间(Hold)检查|
|
||||||
|
|**SF**|慢 (Slow)|快 (Fast)|NMOS慢 + PMOS快|对NMOS敏感路径的建立时间(Setup)检查|
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
3.工艺角如何影响芯片性能?
|
||||||
|
|
||||||
|
##### 3.1. **时序性能**
|
||||||
|
|
||||||
|
- **FF角**:路径延迟最小 → **易发生保持时间违例**(信号过早到达)
|
||||||
|
|
||||||
|
- **SS角**:路径延迟最大 → **易发生建立时间违例**(信号过晚到达)
|
||||||
|
|
||||||
|
- **FS/SF角**:特定路径延迟异常(如FS角下PMOS延迟主导的路径变慢)
|
||||||
|
|
||||||
|
|
||||||
|
##### 3.2. **功耗特性**
|
||||||
|
|
||||||
|
- **静态功耗**:在 **SS + 高温** 下最大(高温指数级增加漏电流)
|
||||||
|
|
||||||
|
- **动态功耗**:在 **FF + 高压** 下最大(高压 & 高翻转率)
|
||||||
|
|
||||||
|
|
||||||
|
##### 3.3. **可靠性风险**
|
||||||
|
|
||||||
|
- **FF + 高压 + 高温**:电迁移(EM)、自发热问题加剧
|
||||||
|
|
||||||
|
- **SS + 低压 + 高温**:晶体管驱动能力不足导致功能失效
|
||||||
|
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
4.为什么工艺角不可或缺?
|
||||||
|
|
||||||
|
4.1. **鲁棒性保障**:预判硅片制造中的波动极限,避免芯片失效。
|
||||||
|
4.2. **PPA平衡**:在性能(Performance)、功耗(Power)、面积(Area)间找到最优解。
|
||||||
|
4.3. **良率锚点**:Corner覆盖越充分,量产良率越高。
|
||||||
|
4.4. **设计迭代依据**:通过Corner仿真定位薄弱电路,指导优化方向(如调整晶体管尺寸、缓冲器插入)。
|
||||||
|
|
@ -0,0 +1,184 @@
|
||||||
|
在计算机的底层架构中,DMA(直接内存访问)技术原本旨在提升数据传输效率,让硬件设备能绕开 CPU,直接与内存高速交互,极大地加快了诸如磁盘存取、图像处理等场景中的数据吞吐速度 。然而,这一特性却被别有用心之人利用,成为恶意攻击的 “帮凶”,如同试图 “越狱” 一般,突破系统既定的安全边界。攻击者借助 DMA,可通过恶意硬件接入,绕开操作系统常规防护,肆意读取敏感数据、篡改内核代码,甚至绕过屏幕密码,威胁用户信息安全与系统稳定。
|
||||||
|
|
||||||
|
此时,IOMMU(输入输出内存管理单元)挺身而出,作为守护系统安全的关键防线,发挥硬核拦截作用。它如同一位严谨的 “交通管制员”,对 DMA 的内存访问行为进行精细管控,重新映射设备地址,限定其可触及的内存范围,让恶意的 DMA “越狱” 企图无处遁形。接下来,就让我们深入这场安全攻防的幕后,一探 IOMMU 如何凭借精妙设计,成功抵御 DMA 的危险冲击 。
|
||||||
|
|
||||||
|
## ****Part1****IOMMU是什么?********
|
||||||
|
|
||||||
|
### 1.1 IOMMU概述
|
||||||
|
|
||||||
|
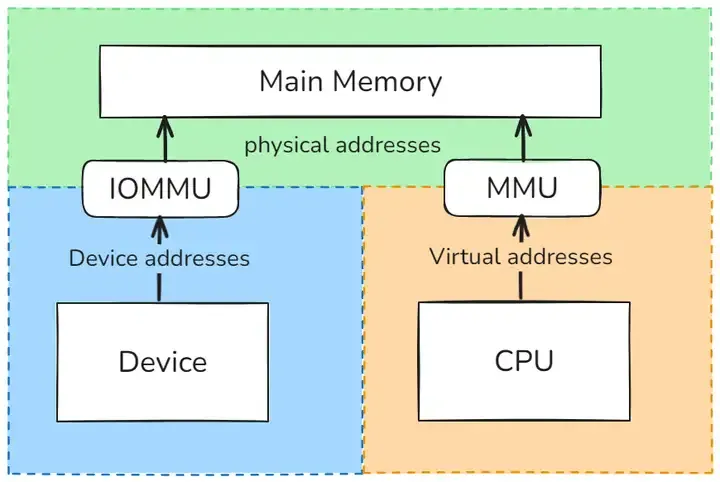
IOMMU,全称 Input/Output Memory Management Unit,即输入输出内存管理单元 ,从名字就可以看出,这是一种内存管理单元(MMU),主要负责将具有直接存储器访问(DMA)能力的 I/O 总线连接至主内存。我们可以把它想象成一个 “翻译官”,在计算机的硬件世界里,承担着至关重要的地址转换工作。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
在计算机系统中,CPU 访问内存时,内存管理单元(MMU)会把 CPU 可见的虚拟地址转换为物理地址。与之类似,IOMMU 的作用是将设备可见的虚拟地址(在 IOMMU 的语境中,也被称为设备地址或 I/O 地址)映射到物理地址。简单来说,当设备想要访问内存时,它给出的地址可能是一个虚拟的 “想法”,而 IOMMU 会将这个 “想法” 翻译成内存能够理解的物理地址,从而实现设备与内存之间的有效沟通。
|
||||||
|
|
||||||
|
除了地址转换,部分 IOMMU 还具备内存保护功能,就像是给内存区域加上了一把 “安全锁”,能够防止故障设备或者恶意设备对内存进行错误访问,确保系统的稳定性和安全性。
|
||||||
|
|
||||||
|
### 1.2 IOMMU 的由来
|
||||||
|
|
||||||
|
在计算机发展的早期阶段,硬件系统的结构相对简单,设备在访问内存时采用的是直接物理寻址方式。那时候,设备可以直接访问物理内存,虽然这种方式简单直接,但也带来了一系列的问题。
|
||||||
|
|
||||||
|
随着计算机技术的发展,计算机系统中的设备种类和数量不断增加,这些设备在进行内存访问时遇到了一些挑战。比如,早期的设备地址空间有限,像 32 位的 PCI 设备,就无法直接访问超过 4GB 的内存 。如果操作系统需要访问超出这个范围的内存,就不得不采用一些复杂且低效的方法,如设置弹跳缓冲区(bounce buffer),即先将数据从高端内存复制到设备可访问的低端内存区域,设备再从这里读取数据,操作完成后再把数据复制回高端内存,这个过程大大增加了数据传输的时间和系统开销。
|
||||||
|
|
||||||
|
再比如,早期的设备访问内存时缺乏有效的内存保护机制,一旦设备驱动程序出现错误,或者设备本身出现故障,就可能导致内存数据被错误地读取或写入,甚至恶意设备可能会对系统内存进行任意访问,从而引发系统崩溃或数据泄露等严重问题。这就好比在一个没有门禁的仓库里,任何人都可以随意进出并拿走或修改里面的物品,安全性完全无法保障。
|
||||||
|
|
||||||
|
为了解决这些问题,IOMMU 应运而生。它的出现就像是在设备和内存之间建立了一个智能的 “中介”,解决了设备内存访问中的寻址限制和内存保护缺失等问题。通过 IOMMU,设备可以访问更大的内存空间,并且能够有效地保护内存不被错误或恶意访问,提高了系统的稳定性和安全性。
|
||||||
|
|
||||||
|
而随着虚拟化技术的兴起,IOMMU 的重要性更是日益凸显。在虚拟化环境中,多个虚拟机共享同一台物理主机的硬件资源。如果没有 IOMMU,当虚拟机中的设备进行 DMA 操作时,就可能会访问到其他虚拟机或者宿主机的内存空间,导致数据泄露和系统不稳定。IOMMU 通过对设备地址的转换和内存访问的控制,确保每个虚拟机的设备只能访问其所属虚拟机的内存,为虚拟机提供了安全隔离的运行环境,使得虚拟化技术能够更加可靠地应用于云计算、数据中心等领域。
|
||||||
|
|
||||||
|
## ****Part2****IOMMU的底层原理********
|
||||||
|
|
||||||
|
IOMMU的核心思想是将物理内存划分为多个区域,每个区域都有一个唯一的ID。这些区域可以是连续的,也可以是不连续的。当CPU需要访问某个内存区域时,IOMMU会将该请求转换为一个虚拟地址,然后将这个虚拟地址与对应的物理地址进行映射。这样,IOMMU是DMA直接内存访问,即设备与内存直接通信,而无需经过CPU。
|
||||||
|
|
||||||
|
**IOMMU的主要组成部分包括:**
|
||||||
|
|
||||||
|
1. MMU(Memory Management Unit):负责将物理内存映射到虚拟地址空间。MMU通常包含一个硬件缓存,用于存储虚拟地址到物理地址的映射关系。此外,MMU还可以实现一些高级功能,如内存保护和地址转换。
|
||||||
|
|
||||||
|
2. IOMMU软件模块:负责管理IOMMU的设置和配置。这通常包括创建和管理内存区域,以及处理来自操作系统的内存访问请求。
|
||||||
|
|
||||||
|
3. 硬件支持:IOMMU需要硬件的支持才能正常工作。这包括一个支持IOMMU的CPU,以及一个能够识别IOMMU的设备驱动程序。
|
||||||
|
|
||||||
|
|
||||||
|
### 2.1 DMA 重映射原理
|
||||||
|
|
||||||
|
IOMMU 的核心功能之一是 DMA 重映射,它就像是一座桥梁,连接了设备和内存之间的地址空间。我们知道,在计算机系统中,内存管理单元(MMU)通过页表将 CPU 的虚拟地址转换为物理地址,使得不同进程的虚拟地址空间能够相互隔离,同时也提高了内存的利用率 。IOMMU 在 DMA 操作中也采用了类似的机制。
|
||||||
|
|
||||||
|
```
|
||||||
|
设备看到的地址空间(连续):[0x1000] [0x2000] [0x3000] [0x4000] ↓ ↓ ↓ ↓实际物理内存(分散):[0xA000] [0xF000] [0xB000] [0xD000]
|
||||||
|
```
|
||||||
|
|
||||||
|
在 IOMMU 的世界里,设备使用的地址被称为 I/O 虚拟地址(IOVA) ,这是设备在发起 DMA 请求时所使用的地址。而 IOMMU 的任务就是将这些 IOVA 转换为物理地址(PA),以便设备能够正确地访问内存。为了实现这一转换,IOMMU 使用了一种类似于 MMU 页表的数据结构,我们可以称之为 I/O 页表。
|
||||||
|
|
||||||
|
当设备发起 DMA 请求时,它会将自己的 Source Identifier(包含 Bus、Device、Func,即总线号、设备号和功能号)包含在请求中。IOMMU 根据这个标识,以 RTADDR_REG(根表地址寄存器)指向空间为基地址,然后利用 Bus、Device、Func 在 Context Table(上下文表)中找到对应的 Context Entry(上下文条目) ,这个 Context Entry 实际上就是页表首地址。找到了页表首地址后,IOMMU 就可以利用页表将设备请求的虚拟地址翻译成物理地址,就像 MMU 利用页表进行地址转换一样。
|
||||||
|
|
||||||
|
例如,在一个具有多个 PCI 设备的系统中,每个 PCI 设备都有自己的 Source Identifier。当某个 PCI 设备发起 DMA 请求时,IOMMU 会根据其 Source Identifier 在 Context Table 中找到对应的 Context Entry,进而定位到该设备专用的页表。通过这个页表,IOMMU 将设备请求的 IOVA 转换为正确的物理地址,确保数据能够准确无误地在设备和内存之间传输。
|
||||||
|
|
||||||
|
这种机制不仅解决了设备地址空间有限的问题,还为系统提供了内存保护功能。因为设备只能通过 IOMMU 访问经过映射的物理地址,所以即使设备驱动程序出现错误,也无法直接访问到非法的内存区域,从而提高了系统的稳定性和安全性。
|
||||||
|
|
||||||
|
### 2.2中断重映射原理
|
||||||
|
|
||||||
|
除了 DMA 重映射,IOMMU 还具备中断重映射的功能,这在虚拟化场景中尤为重要。在传统的非虚拟化环境中,设备的中断请求可以直接发送到 CPU,由操作系统进行处理。但在虚拟化环境下,情况变得复杂起来。当一个设备被直通给虚拟机时,它的中断请求需要被正确地投递到对应的虚拟机中,而不是直接发送到宿主机的 CPU,这就需要 IOMMU 来进行中断重映射。
|
||||||
|
|
||||||
|
在现代计算机系统中,许多设备使用以 message signal 形式触发的中断,如 MSI(Message Signaled Interrupts)或 MSIX(Message Signaled Interrupts Extension) 。这些中断的实现方式是通过向特定的地址发起一个 DMA 写操作来触发。IOMMU 正是通过识别这个特定的地址前缀(如 0xFEE)来判断某个 DMA 写操作是否是一个中断请求。
|
||||||
|
|
||||||
|
以 PCI 或 PCIE 设备为例,在中断重映射模式下,当设备发起 MSI 或 MSIX 中断请求时,其 message address 和 message data 的格式会有所不同。比如,address register bit 4 需要置为 1,表示为中断重映射模式;address register bit 3 表示的是 SubHandle Valid(SHV) ,这里强制为 1 即 SubHandle 是有效的;address register bits 19:5 表示的是 interrupt_index 的 0~14 位,bit 2 表示的是 interrupt_index 的第 15 位。这些信息用于 IOMMU 在中断重映射表中查找对应的中断描述符,从而确定中断的目标虚拟机或 CPU。
|
||||||
|
|
||||||
|
再看 ioapic(I/O Advanced Programmable Interrupt Controller) ,它在系统中负责中断的路由。在中断重映射模式下,ioapic 的 redirection table entry(重定向表项)的格式也发生了变化,新增了一些字段,如 bits 49:63 对应的是 interrupt_index [14:0],bit 11 对应的是 interrup_index [15] ,bit 48 表示是否为 remapping 的中断格式等。这些字段帮助 ioapic 在 IOMMU 的协助下,将设备的中断请求正确地路由到目标位置。
|
||||||
|
|
||||||
|
当 IOMMU 接收到一个中断请求时,它会根据请求中的相关信息(如 interrupt_index、SHV 等)在中断重映射表(Interrupt Remapping Table)中查找对应的中断描述符(Interrupt Remapping Table Entry,IRTE) 。找到 IRTE 后,IOMMU 根据其中记录的信息,将中断请求发送到正确的目标,可能是虚拟机中的虚拟 CPU,也可能是宿主机的特定 CPU 核心,从而实现了中断在虚拟化环境中的正确投递和处理。
|
||||||
|
|
||||||
|
中断重映射功能确保了虚拟化环境中设备中断的正确处理,避免了中断混乱和错误投递的问题,为虚拟机的稳定运行提供了保障。
|
||||||
|
|
||||||
|
### 2.3IOMMU的主要实现
|
||||||
|
|
||||||
|
**(1)Intel VT-d (Virtualization Technology for Directed I/O)**
|
||||||
|
|
||||||
|
```
|
||||||
|
// Intel VT-d 功能特性- DMA 重映射- 中断重映射- 设备隔离- 热插拔支持
|
||||||
|
```
|
||||||
|
|
||||||
|
**(2)AMD-Vi (AMD I/O Virtualization)**
|
||||||
|
|
||||||
|
```
|
||||||
|
// AMD-Vi 功能特性 - I/O 虚拟化- 设备表管理- 命令处理- 事件日志
|
||||||
|
```
|
||||||
|
|
||||||
|
**(3) ARM SMMU (System Memory Management Unit)**
|
||||||
|
|
||||||
|
```
|
||||||
|
// ARM SMMU 功能特性- 流表 (Stream Table)- 上下文描述符- 页表遍历- 故障处理
|
||||||
|
```
|
||||||
|
|
||||||
|
## ****Part3****IOMMU的应用场景********
|
||||||
|
|
||||||
|
随着云计算和虚拟化技术的飞速发展,虚拟化环境在企业和数据中心中得到了广泛应用。在虚拟化环境中,多个虚拟机共享同一物理硬件资源,这就对系统的安全性和隔离性提出了极高的要求。IOMMU 作为虚拟化技术的关键支撑,在保障虚拟机之间的隔离与安全方面发挥着不可或缺的作用。
|
||||||
|
|
||||||
|
在一个典型的云计算数据中心中,可能同时运行着多个不同租户的虚拟机,每个虚拟机都承载着不同的业务应用,这些应用可能包含着租户的敏感数据。如果没有有效的隔离机制,一旦某个虚拟机中的 DMA 操作出现异常或被恶意利用,就可能导致其他虚拟机的数据泄露或系统故障。
|
||||||
|
|
||||||
|
IOMMU 通过地址转换和访问控制功能,为每个虚拟机建立了独立的内存访问空间 。当虚拟机中的设备发起 DMA 请求时,IOMMU 会将虚拟机的设备地址(GPA)转换为物理地址(PA),并确保该请求只能访问分配给该虚拟机的内存区域。即使某个虚拟机被黑客攻击,黑客试图利用 DMA 操作窃取其他虚拟机的数据,IOMMU 也会严格按照访问权限规则,拦截非法的内存访问请求,从而保障了其他虚拟机的数据安全和正常运行。
|
||||||
|
|
||||||
|
假设在一个虚拟化的服务器环境中,有一台虚拟机运行着企业的财务系统,存储着重要的财务数据;另一台虚拟机运行着企业的办公自动化系统。如果没有 IOMMU 的保护,当办公自动化系统所在的虚拟机中存在恶意软件,利用 DMA “越狱” 尝试访问财务系统所在虚拟机的内存时,就可能导致财务数据泄露。而有了 IOMMU,它会对每一个 DMA 请求进行严格审查,一旦发现办公自动化系统虚拟机的 DMA 请求试图访问财务系统虚拟机的内存区域,就会立即阻止该请求,确保了财务数据的安全性和保密性 。IOMMU 在虚拟化环境中的应用,极大地提高了云计算和虚拟化系统的安全性和可靠性,为企业和用户的数据安全提供了坚实的保障,推动了虚拟化技术在更广泛领域的应用和发展。
|
||||||
|
|
||||||
|
### 3.1虚拟化环境
|
||||||
|
|
||||||
|
IOMMU 是设备直通 (Device Passthrough) 的基础:
|
||||||
|
|
||||||
|
```
|
||||||
|
# KVM 虚拟机配置示例<hostdev mode='subsystem' type='pci' managed='yes'> <driver name='vfio'/> <source> <address domain='0x0000' bus='0x01' slot='0x00' function='0x0'/> </source></hostdev>
|
||||||
|
```
|
||||||
|
|
||||||
|
**VFIO (Virtual Function I/O) 框架**
|
||||||
|
|
||||||
|
```
|
||||||
|
// VFIO 使用 IOMMU 实现设备隔离struct vfio_group *group;struct vfio_device *device;// 将设备绑定到 VFIO 驱动echo 0000:01:00.0 > /sys/bus/pci/drivers/nvidia/unbindecho 0000:01:00.0 > /sys/bus/pci/drivers/vfio-pci/bind// 在虚拟机中直接使用设备qemu-kvm -device vfio-pci,host=01:00.0 ...
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3.2容器化和微服务
|
||||||
|
|
||||||
|
```
|
||||||
|
# Docker 容器使用 GPU 示例docker run --gpus all \ --device=/dev/dri \ --security-opt apparmor:unconfined \ nvidia/cuda:11.0-base
|
||||||
|
```
|
||||||
|
|
||||||
|
### 3.3安全隔离
|
||||||
|
|
||||||
|
```
|
||||||
|
// 防止恶意设备的 DMA 攻击Bad Device ─── DMA Request ──→ IOMMU ──→ Access Denied (恶意地址) (权限检查失败)
|
||||||
|
```
|
||||||
|
|
||||||
|
## ****Part4****IOMMU配置和管理********
|
||||||
|
|
||||||
|
### 4.1系统启动配置
|
||||||
|
|
||||||
|
```
|
||||||
|
# GRUB 配置启用 IOMMU# Intel 系统GRUB_CMDLINE_LINUX="intel_iommu=on iommu=pt"# AMD 系统 GRUB_CMDLINE_LINUX="amd_iommu=on iommu=pt"# 更新 GRUBsudo update-grubsudo reboot
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4.2检查 IOMMU 状态
|
||||||
|
|
||||||
|
```
|
||||||
|
# 检查 IOMMU 是否启用dmesg | grep -i iommudmesg | grep -i dmar # Intel VT-ddmesg | grep -i amd_iommu # AMD-Vi# 查看 IOMMU 组find /sys/kernel/iommu_groups/ -type l# 查看设备的 IOMMU 组ls -la /sys/bus/pci/devices/0000:01:00.0/iommu_group
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4.3 IOMMU 组管理
|
||||||
|
|
||||||
|
```
|
||||||
|
#!/bin/bash# 显示所有 IOMMU 组和对应设备for g in /sys/kernel/iommu_groups/*; do echo "IOMMU Group ${g##*/}:" for d in $g/devices/*; do echo -e "\t$(lspci -nns ${d##*/})" donedone
|
||||||
|
```
|
||||||
|
|
||||||
|
## ****Part5****IOMMU编程接口********
|
||||||
|
|
||||||
|
### 5.1内核IOMMU API
|
||||||
|
|
||||||
|
```
|
||||||
|
#include <linux/iommu.h>// 分配 IOMMU 域struct iommu_domain *domain = iommu_domain_alloc(&pci_bus_type);// 附加设备到域iommu_attach_device(domain, &pdev->dev);// 建立映射iommu_map(domain, iova, paddr, size, IOMMU_READ | IOMMU_WRITE);// 取消映射iommu_unmap(domain, iova, size);// 分离设备iommu_detach_device(domain, &pdev->dev);
|
||||||
|
```
|
||||||
|
|
||||||
|
### 5.2用户空间VFIO API
|
||||||
|
|
||||||
|
```
|
||||||
|
#include <linux/vfio.h>// 打开 VFIO 容器int container = open("/dev/vfio/vfio", O_RDWR);// 打开 IOMMU 组int group = open("/dev/vfio/1", O_RDWR);// 设置 IOMMU 类型ioctl(container, VFIO_SET_IOMMU, VFIO_TYPE1_IOMMU);// DMA 映射struct vfio_iommu_type1_dma_map dma_map = { .argsz = sizeof(dma_map), .flags = VFIO_DMA_MAP_FLAG_READ | VFIO_DMA_MAP_FLAG_WRITE, .vaddr = (uintptr_t)buffer, .iova = device_address, .size = buffer_size,};ioctl(container, VFIO_IOMMU_MAP_DMA, &dma_map);
|
||||||
|
```
|
||||||
|
|
||||||
|
## ****Part6****IOMMU硬核拦截原理剖析********
|
||||||
|
|
||||||
|
### 6.1地址翻译:识破 “伪装”
|
||||||
|
|
||||||
|
当 DMA 发起访问请求时,IOMMU 首先会对请求中的 I/O 虚拟地址(IOVA)进行地址翻译 。IOMMU 中维护着类似于 CPU 页表的 IO 页表,通过查询 IO 页表,IOMMU 可以将 IOVA 准确地转换为物理地址(PA) 。这个过程就像是在一本详细的地址翻译词典中查找对应的翻译,词典(IO 页表)里记录着 IOVA 和 PA 的对应关系,IOMMU 根据这个关系完成翻译工作。
|
||||||
|
|
||||||
|
假设一个设备的DMA请求中包含的 IOVA 是 0x1000,IOMMU 通过查询 IO 页表,发现这个 IOVA 对应的 PA 是 0x20000,那么 IOMMU 就会将这个正确的物理地址传递给内存访问操作。通过这种地址翻译机制,IOMMU 能够清晰地识别 DMA 请求的真实目标。如果 DMA 请求的 IOVA 存在异常,比如指向了一个不存在的或非法的地址映射,IOMMU 就能立刻察觉,从而防止 DMA 访问非法内存地址 。这就好比一个人拿着错误的地图导航(非法的 IOVA),而 IOMMU 作为专业的导航修正员,能够发现错误并阻止其前往错误的目的地(非法内存区域)。
|
||||||
|
|
||||||
|
### 6.2访问控制:严守 “关卡”
|
||||||
|
|
||||||
|
在完成地址翻译后,IOMMU 并不会立刻放行 DMA 请求,而是会对设备对目标内存的访问权限进行严格检查 。IOMMU 中存储着每个设备的访问权限信息,这些信息规定了设备可以访问的内存区域以及访问的类型(读、写、执行等) 。就像每个员工都有自己的门禁权限,只能进入被授权的办公室区域,设备也只能访问被授予权限的内存区域。
|
||||||
|
|
||||||
|
例如,一个网络设备被授权只能读取内存中特定的网络数据缓冲区,当它发起 DMA 请求想要写入其他内存区域时,IOMMU 会迅速检查到这种越权行为,立即阻止该 DMA 请求的执行,并向系统报告错误 。通过这样的权限检查,IOMMU 就像是一个忠诚的卫士,严守着内存的 “关卡”,有效地阻止了 DMA 对未经授权内存区域的读写操作,实现了对系统内存的严密保护,确保了系统内存中数据的安全性和完整性。
|
||||||
|
|
||||||
|
### 6.3多级页表与缓存机制:高效运作的秘诀
|
||||||
|
|
||||||
|
为了提高地址翻译的效率和灵活性,IOMMU采用了多级页表结构 。以常见的三级页表为例,虚拟地址会被划分为多个部分,每个部分对应不同级别的页表索引 。当IOMMU接收到一个 IOVA 时,它首先会根据虚拟地址的最高位部分作为索引,在一级页表(页全局目录)中查找对应的页目录项(PDE) 。
|
||||||
|
|
||||||
|
这个 PDE 指向二级页表(页目录表),IOMMU再根据虚拟地址的次高位部分在二级页表中查找对应的页表项(PTE) ,最终通过PTE找到对应的物理页框,完成地址翻译 。这种多级页表结构就像一个层层分类的大型图书馆索引系统,每一级页表都是一个分类索引,通过逐级查找,能够快速定位到所需的物理地址,大大提高了地址翻译的效率,同时也使得内存的管理更加灵活,可以支持更大的地址空间。
|
||||||
|
|
||||||
|
为了进一步加速地址翻译过程,IOMMU 还引入了 IOTLB(I/O Translation Lookaside Buffer) ,即 I/O 转译后备缓冲器,它相当于 IO 页表的高速缓存 。IOTLB 中缓存了最近使用的 IOVA 到 PA 的地址转换信息 。当 IOMMU 接收到 DMA 请求时,它会首先在 IOTLB 中查找是否有对应的地址转换信息 。如果 IOTLB 命中,即找到了缓存的转换信息,IOMMU 可以直接使用这些信息快速完成地址翻译,而无需再去查询多级页表,大大节省了时间 。
|
||||||
|
|
||||||
|
只有当 IOTLB 未命中时,IOMMU 才会去查询多级页表进行地址翻译 。这就好比你经常使用的常用物品放在一个随手可及的小抽屉(IOTLB)里,当你需要时可以快速拿到,而不需要去大型仓库(多级页表)中慢慢寻找,大大提高了效率。通过多级页表和 IOTLB 的协同工作,在面对大量 DMA 请求时,IOMMU 仍能快速、准确地进行拦截操作,保障系统的稳定运行。
|
||||||
Loading…
Reference in New Issue